介绍
这是一个介绍Polars DataFrame library的指南。它的目标是通过示例演示以及与其他类似解决方案进行比较,向您介绍Polars。这里介绍了一些设计选择。该指南还将向您介绍Polars的最佳使用。
尽管Polars完全是用Rust写的(没有运行时开销!)使用 Arrow -- 原生 Rust 实现的arrow2 -- 作为它的底基。本指南中的示例主要使用其更高级的语言绑定。高级绑定只作为核心库中实现的功能的简要的包装。
对于 Pandas 使用者, 我们的Python package 提供最简单的方式来入门Polars.
目标与非目标
Polars的目标是提供一个闪电般的DataFrame库,利用所有机器上的可用核心。不像dask这样的工具——它试图并行化现有的单线程库,比如NumPy和Pandas——Polars是从头开始编写的,旨在并行化DataFrame上的查询。
Polars不遗余力地:
- 减少冗余拷贝
- 高效地遍历内存缓存
- 最小化并行中的争用
Polars是懒惰和半懒惰的。它可以让你急切地完成大部分工作,就像Pandas一样,但是
它还提供了强大的表达式语法,可以在查询引擎中对其进行优化和执行。
在lazy Polars中,我们能够对整个查询进行查询优化,进一步提高性能和内存压力。
Polars以逻辑计划跟踪您的查询。这计划在运行前会经过优化和重新排序。当请求结果时,Polars将可执行的任务分发给不同的使用立即反馈的算法的API的执行器并获取结果。因为优化器和执行器知晓整个查询上下文,依赖于独立数据源的计算得以在运行时被动态地并行化。

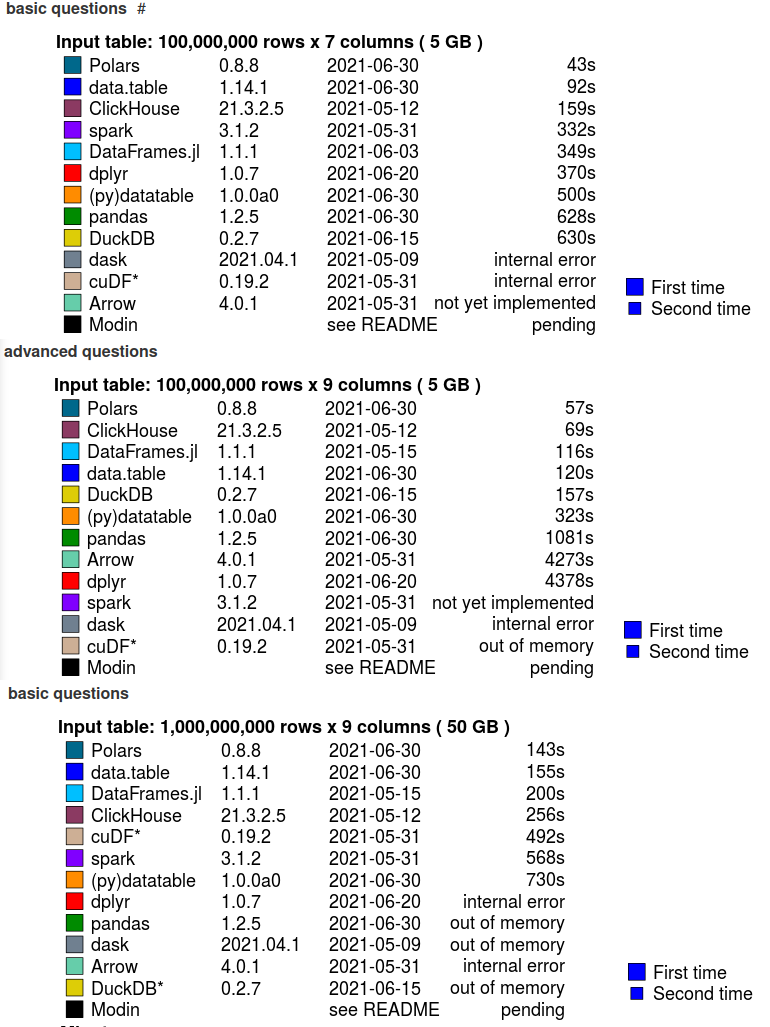
性能 🚀🚀
Polars的速度非常快,事实上是目前性能最好的解决方案之一。参见h2oai的db基准测试中的结果。下图显示了产生结果的最大数据集。
当前状态
下面是Polars能够实现其目标的功能的简明列表:
- Copy-on-write (COW) 语义学
- “自由”克隆(Clone)
- 便捷的追加(append)
- 没有克隆(clone)的追加(append)
- 面向列的数据存储
- 无区块管理器(即可预测的性能)
- 缺少用位掩码(bitmask)指示的值
- NaN和missing不一样
- 位掩码(bitmask)优化
- 高效算法
- 非常快的IO
- 它的csv和parquet阅读器是现存速度最快的阅读器之一
- 查询优化
- 谓词(Predicate)下推
- 扫描级过滤
- 投影下推
- 扫描级投影
- 聚合下推
- 扫描级聚合
- 简化表达式
- 物理计划的并行执行
- 基于基数的分组调度
- 基于数据基数的分组策略
- 谓词(Predicate)下推
- SIMD矢量化
NumPy通用函数
致谢
Polars的开发是由
