介绍
这是一个介绍Polars DataFrame library的指南。它的目标是通过示例演示以及与其他类似解决方案进行比较,向您介绍Polars。这里介绍了一些设计选择。该指南还将向您介绍Polars的最佳使用。
尽管Polars完全是用Rust写的(没有运行时开销!)使用 Arrow -- 原生 Rust 实现的arrow2 -- 作为它的底基。本指南中的示例主要使用其更高级的语言绑定。高级绑定只作为核心库中实现的功能的简要的包装。
对于 Pandas 使用者, 我们的Python package 提供最简单的方式来入门Polars.
目标与非目标
Polars的目标是提供一个闪电般的DataFrame库,利用所有机器上的可用核心。不像dask这样的工具——它试图并行化现有的单线程库,比如NumPy和Pandas——Polars是从头开始编写的,旨在并行化DataFrame上的查询。
Polars不遗余力地:
- 减少冗余拷贝
- 高效地遍历内存缓存
- 最小化并行中的争用
Polars是懒惰和半懒惰的。它可以让你急切地完成大部分工作,就像Pandas一样,但是
它还提供了强大的表达式语法,可以在查询引擎中对其进行优化和执行。
在lazy Polars中,我们能够对整个查询进行查询优化,进一步提高性能和内存压力。
Polars以逻辑计划跟踪您的查询。这计划在运行前会经过优化和重新排序。当请求结果时,Polars将可执行的任务分发给不同的使用立即反馈的算法的API的执行器并获取结果。因为优化器和执行器知晓整个查询上下文,依赖于独立数据源的计算得以在运行时被动态地并行化。

性能 🚀🚀
Polars的速度非常快,事实上是目前性能最好的解决方案之一。参见h2oai的db基准测试中的结果。下图显示了产生结果的最大数据集。
当前状态
下面是Polars能够实现其目标的功能的简明列表:
- Copy-on-write (COW) 语义学
- “自由”克隆(Clone)
- 便捷的追加(append)
- 没有克隆(clone)的追加(append)
- 面向列的数据存储
- 无区块管理器(即可预测的性能)
- 缺少用位掩码(bitmask)指示的值
- NaN和missing不一样
- 位掩码(bitmask)优化
- 高效算法
- 非常快的IO
- 它的csv和parquet阅读器是现存速度最快的阅读器之一
- 查询优化
- 谓词(Predicate)下推
- 扫描级过滤
- 投影下推
- 扫描级投影
- 聚合下推
- 扫描级聚合
- 简化表达式
- 物理计划的并行执行
- 基于基数的分组调度
- 基于数据基数的分组策略
- 谓词(Predicate)下推
- SIMD矢量化
NumPy通用函数
致谢
Polars的开发是由

快速入门
安装
采用 pip install 即可安装 Polars 。
$ pip install polars
所有的二进制包都是基于 Python v3.6+ 构建的。
实例
下面的例子中我们读入并解析一个 CSV 文件,过滤后紧跟一个 groupby 分组求和操作(该例子仅在Python中演示,因为对于Rust而言,即时执行的API并不推荐):
import polars as pl
df = pl.read_csv("https://j.mp/iriscsv")
print(df.filter(pl.col("sepal_length") > 5)
.groupby("species")
.agg(pl.all().sum())
)
上面的代码输出如下:
shape: (3, 5)
╭──────────────┬──────────────────┬─────────────────┬──────────────────┬─────────────────╮
│ species ┆ sepal_length_sum ┆ sepal_width_sum ┆ petal_length_sum ┆ petal_width_sum │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ f64 ┆ f64 ┆ f64 │
╞══════════════╪══════════════════╪═════════════════╪══════════════════╪═════════════════╡
│ "virginica" ┆ 324.5 ┆ 146.2 ┆ 273.1 ┆ 99.6 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ "versicolor" ┆ 281.9 ┆ 131.8 ┆ 202.9 ┆ 63.3 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ "setosa" ┆ 116.9 ┆ 81.7 ┆ 33.2 ┆ 6.1 │
╰──────────────┴──────────────────┴─────────────────┴──────────────────┴─────────────────╯
如上所示, Polars 可以格式化输出,包括作为表头的列名和数据类型。
延迟执行示例
上面的例子我们也可以采用延迟执行方式执行:
import polars as pl
print(
pl.read_csv("https://j.mp/iriscsv")
.lazy()
.filter(pl.col("sepal_length") > 5)
.groupby("species")
.agg(pl.all().sum())
.collect()
)
如果数据文件保存在本地,我们还可以使用 scan_csv 来实现延迟执行查询。
参考
Python API 可以参考:Fix Me.
延迟执行 API
延迟执行 API 会构建一个查询计划。在调用 LazyFrame.collect() 或者 LazyFrame.fetch() 之前,Polars 不会执行任何操作。这种方式可以让 Polars 了解查询的所有操作,并依据这些操作进行优化并选择最佳的算法执行。
从即时执行变更为延迟执行非常简单,只需要在已有调用基础上添加 .lazy() 和 .collect() 即可。
正如之前看到的例子一样:
import polars as pl
print(
pl.read_csv("https://j.mp/iriscsv")
.lazy()
.filter(pl.col("sepal_length") > 5)
.groupby("species")
.agg(pl.all().sum())
.collect()
)
介绍
Polars有一个强大的概念叫做表达式,这是Polars表现十分高效的核心原因之一。
表达式是许多数据科学计算的核心操作,常见的包括:
- 从某列中取某行
- 将某列乘上某些数
- 从日期提取年份
- 将一系列字符串转换成小写
- ....
当然,表达式也被用于其他操作中:
- 通过
groupby操作分组求均值 - 通过
groupby操作分组求数量 - 多列求和
Polars通过以下方式实现高效的核心数据转换:
- 对每个表达式进行自动的查询优化
- 对多列表达式自动并行处理
Polars表达式是一个从列(Series)到列的映射(或者从数学角度上是Fn(Series) -> Series),可以在各种上下文中使用,这意味着它们有一个列(Series)作为输入,一个列(Series)作为输出。通过查看这个函数定义,我们可以看到Expr的输出也可以用作Expr的输入。
这听起来可能有点抽象,所以让我们从一个例子开始。
Polars 表达式
下面是一个表达式:
pl.col("foo").sort().head(2)
这个表达式的意思是:
- 选择
foo列 - 给
foo排序 - 然后取排序后的前两个值
表达式的强大之处在于:每一个表达式都会生成一个新的表达式,他们可以被串在一起。
你也可以把多个表达式放入一个 Polars 的执行上下文中。
比如,下面我们通过 df.select 将两个表达式放在同一个执行上下文中:
df.select([
pl.col("foo").sort().head(2),
pl.col("bar").filter(pl.col("foo") == 1).sum()
])
这里的两个表达式是并行执行的,这就意味着 Polars 表达式可以易并行计算(即无通讯并行)。
值得注意的是,每一个表达式的执行可能同时存在更多的并行。
表达式举例
这一小节我们通过例子了解表达式。首先,创建一个数据集:
import polars as pl
import numpy as np
np.random.seed(12) # 设置随机数种子(保证每次生成的随机数相同)
df = pl.DataFrame(
{
"nrs": [1, 2, 3, None, 5],
"names": ["foo", "ham", "spam", "egg", None],
"random": np.random.rand(5),
"groups": ["A", "A", "B", "C", "B"],
}
)
print(df)
shape: (5, 4)
┌──────┬───────┬──────────┬────────┐
│ nrs ┆ names ┆ random ┆ groups │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞══════╪═══════╪══════════╪════════╡
│ 1 ┆ foo ┆ 0.154163 ┆ A │
│ 2 ┆ ham ┆ 0.74005 ┆ A │
│ 3 ┆ spam ┆ 0.263315 ┆ B │
│ null ┆ egg ┆ 0.533739 ┆ C │
│ 5 ┆ null ┆ 0.014575 ┆ B │
└──────┴───────┴──────────┴────────┘
你可以通过表达式做很多事情,他们的表达能力很强以至于很多时候你有多种不同的方法得到同一个计算结果。 为了更好的理解表达式,让我们看更多的例子。
统计不重复元素数量
我们可以统计一列中不重复元素的数量。注意这里我们采用了两种不同的方法得到了同一个结果。为了避免列名重复,
我们使用 alias 即别名表达式来重命名列名。
out = df.select(
[
pl.col("names").n_unique().alias("unique_names_1"),
pl.col("names").unique().count().alias("unique_names_2"),
]
)
print(out)
shape: (1, 2)
┌────────────────┬────────────────┐
│ unique_names_1 ┆ unique_names_2 │
│ --- ┆ --- │
│ u32 ┆ u32 │
╞════════════════╪════════════════╡
│ 5 ┆ 5 │
└────────────────┴────────────────┘
不同的聚合操作
我们可以完成不同的聚合操作,下面是一些例子,当然还有更多操作比如:median, mean, first等等。
out = df.select(
[
pl.sum("random").alias("sum"), # 对random列求和并新增一列
pl.min("random").alias("min"), # 对random列求最小值并新增一列
pl.max("random").alias("max"), # 对random列求最大值并新增一列
pl.col("random").max().alias("other_max"), # 另一种求最大值的方式
pl.std("random").alias("std dev"), # 对random列求标准差并新增一列
pl.var("random").alias("variance"), # 对random列求方差并新增一列
]
)
print(out)
shape: (1, 6)
┌──────────┬──────────┬─────────┬───────────┬──────────┬──────────┐
│ sum ┆ min ┆ max ┆ other_max ┆ std dev ┆ variance │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ f64 ┆ f64 ┆ f64 ┆ f64 ┆ f64 ┆ f64 │
╞══════════╪══════════╪═════════╪═══════════╪══════════╪══════════╡
│ 1.705842 ┆ 0.014575 ┆ 0.74005 ┆ 0.74005 ┆ 0.293209 ┆ 0.085971 │
└──────────┴──────────┴─────────┴───────────┴──────────┴──────────┘
过滤和条件选择
当然,我们可以做一些复杂的事情,比如下面的例子中我们统计所有以 am 结尾的名字。
out = df.select(
[
pl.col("names").filter(pl.col("names").str.contains(r"am$")).count(), # str命名空间使用正则表达式
]
)
print(df)
shape: (1, 1)
┌───────┐
│ names │
│ --- │
│ u32 │
╞═══════╡
│ 2 │
└───────┘
二元函数和修改
下面的实例中,用一个条件语句创建一个表达式,我们使用 when -> then -> otherwise 的模式。
when 函数需要一个谓词表达式 (Predicate expression,因此返回一个布尔类型的 Series) 。
then 函数需要传入当谓词表达式结果为真时执行的表达式,而 otherwise 函数需要传入谓词表达式结果为
假时的表达式。
你可以传入任何表达式,包括简单的pl.col("foo"), pl.lit(3), pl.lit("bar")等等。
最终,我们把结果与一个 sum 表达式相乘。
out = df.select(
[
pl.when(pl.col("random") > 0.5).then(0).otherwise(pl.col("random")) * pl.sum("nrs"),
]
)
print(df)
shape: (5, 1)
┌──────────┐
│ literal │
│ --- │
│ f64 │
╞══════════╡
│ 1.695791 │
│ 0.0 │
│ 2.896465 │
│ 0.0 │
│ 0.160325 │
└──────────┘
窗口表达式
一个 polars 表达式可以隐式地进行 GROUPBY(分组)、AGGREGATION(聚合) 以及 JOIN(联合) 操作。
在下面的例子中,使用over函数,我们通过 groups 进行分组,在 random 列执行聚合加法。在下一个表达式中,
通过 names 进行分组,在 random 列执行聚合列表操作。
这些窗口函数还可以与其他表达式组合形成一个高效计算分组统计指标计算方法。
更多的分组函数参考这里。
df = df.select(
[
pl.col("*"), # 选择所有列
pl.col("random").sum().over("groups").alias("sum[random]/groups"),
]
)
print(df)
shape: (5, 5)
┌──────┬───────┬──────────┬────────┬────────────────────┐
│ nrs ┆ names ┆ random ┆ groups ┆ sum[random]/groups │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str ┆ f64 │
╞══════╪═══════╪══════════╪════════╪════════════════════╡
│ 1 ┆ foo ┆ 0.154163 ┆ A ┆ 0.894213 │
│ 2 ┆ ham ┆ 0.74005 ┆ A ┆ 0.894213 │
│ 3 ┆ spam ┆ 0.263315 ┆ B ┆ 0.27789 │
│ null ┆ egg ┆ 0.533739 ┆ C ┆ 0.533739 │
│ 5 ┆ null ┆ 0.014575 ┆ B ┆ 0.27789 │
└──────┴───────┴──────────┴────────┴────────────────────┘
结论
这里我们看到的表达式仅仅是冰山一角。Polars 提供了很多表达式,而且他们可以通过多种方式组合。
本篇文档是一个表达式的简介,帮助用户稍微了解如何使用表达式。下一章中我们会讨论在哪些场景
中可以使用表达式。在接下来的章节中,我们还会介绍如何在不同的 groupby 场景中使用表达式,并
确保 Polars 可以并行执行计算。
上下文
表达式几乎可以在任何地方使用,但是表达式需要一个上下文,这些上下文包括:
- 选择:
df.select([..]) - 分组集合:
df.groupby(..).agg([..]) - 横向堆叠(hstack) 或者增加列:
df.with_columns([..])
语法糖
需要上下文的主要原因是:即使在即时执行中,你也在使用 Polars 的延迟执行API。 比如如下代码实例:
df.groupby("foo").agg([pl.col("bar").sum()])
去掉语法糖后:
(df.lazy().groupby("foo").agg([pl.col("bar").sum()])).collect()
这种设计可以让 Polars 把表达式推送给查询引擎,进行一些优化和缓存操作。
select 上下文
在 select 上下文中,选择操作是按照列进行的。在选择向下文的表达式必须要返回 Series 并且这些 Series 需要有相同的长度或者长度为1。
一个长度为 1 的 Series 会将 DataFrame 的一列赋予完全一样的值(这个值来自Series)。
注意,select 可能会返回一个新的列,这个列可能是一些聚合的结果、一些表达式的组合或者常量。
选择上下文
out = df.select(
[
pl.sum("nrs"),
pl.col("names").sort(),
pl.col("names").first().alias("first name"),
(pl.mean("nrs") * 10).alias("10xnrs"),
]
)
print(out)
shape: (5, 4)
┌─────┬───────┬────────────┬────────┐
│ nrs ┆ names ┆ first name ┆ 10xnrs │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ f64 │
╞═════╪═══════╪════════════╪════════╡
│ 11 ┆ null ┆ foo ┆ 27.5 │
│ 11 ┆ egg ┆ foo ┆ 27.5 │
│ 11 ┆ foo ┆ foo ┆ 27.5 │
│ 11 ┆ ham ┆ foo ┆ 27.5 │
│ 11 ┆ spam ┆ foo ┆ 27.5 │
└─────┴───────┴────────────┴────────┘
添加列
采用 with_columns 给 DataFrame 增加列同样也是选择上下文。
df = df.with_columns(
[
pl.sum("nrs").alias("nrs_sum"),
pl.col("random").count().alias("count"),
]
)
print(out)
shape: (5, 6)
┌──────┬───────┬──────────┬────────┬─────────┬───────┐
│ nrs ┆ names ┆ random ┆ groups ┆ nrs_sum ┆ count │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str ┆ i64 ┆ u32 │
╞══════╪═══════╪══════════╪════════╪═════════╪═══════╡
│ 1 ┆ foo ┆ 0.154163 ┆ A ┆ 11 ┆ 5 │
│ 2 ┆ ham ┆ 0.74005 ┆ A ┆ 11 ┆ 5 │
│ 3 ┆ spam ┆ 0.263315 ┆ B ┆ 11 ┆ 5 │
│ null ┆ egg ┆ 0.533739 ┆ C ┆ 11 ┆ 5 │
│ 5 ┆ null ┆ 0.014575 ┆ B ┆ 11 ┆ 5 │
└──────┴───────┴──────────┴────────┴─────────┴───────┘
Groupby 上下文
在 groupby 上下文中的表达式主要作用域分组上,因此他们会返回任意长度(每个组可能有不同数量的成员)。
out = df.groupby("groups").agg(
[
pl.sum("nrs"), # 通过groups列对nrs求和
pl.col("random").count().alias("count"), # 记录组数
# 如果name != null记录random列的和
pl.col("random").filter(pl.col("names").is_not_null()).sum().suffix("_sum"),
pl.col("names").reverse().alias(("reversed names")),
]
)
print(out)
shape: (3, 5)
┌────────┬─────┬───────┬────────────┬────────────────┐
│ groups ┆ nrs ┆ count ┆ random_sum ┆ reversed names │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ u32 ┆ f64 ┆ list[str] │
╞════════╪═════╪═══════╪════════════╪════════════════╡
│ C ┆ 0 ┆ 1 ┆ 0.533739 ┆ ["egg"] │
│ A ┆ 3 ┆ 2 ┆ 0.894213 ┆ ["ham", "foo"] │
│ B ┆ 8 ┆ 2 ┆ 0.263315 ┆ [null, "spam"] │
└────────┴─────┴───────┴────────────┴────────────────┘
除了标准的 groupby,还有 groupby_dynamic 和 groupby_rolling 也属于 Groupby 上下文。
分组
多线程
处理表状数据最高效的方式就是通过“分割-处理-组合”的方式并行地进行。这样的操作正是 Polars 的
分组操作的核心,也是 Polars 如此高效的秘密。特别指出,分割和处理都是多线程执行的。
下面的例子展示了分组操作的流程:

对于分割阶段的哈希操作,Polars 使用了无锁多线程方式,如下图所示:

这样的并行操作可以让分组和联合操作非常非常高效。
更多解释参考 这篇博客
不要“杀死”并行
众所周知,Python 慢、水平拓展不好。除了因为是解释型语言,Python 还收到全局解释器锁,GIL。
这就意味着,如果你传入一个 lambda 或者 Python 自定义函数,Polars 速度会被限制,即
无法使用多核进行并行计算。
这是个很糟糕的情况,特别我们在做 .groupby 的时候会经常传入 lambda 函数。虽然 Polars
支持这种操作,但是请注意 Python 的限制,特别是解释器和GIL。
为了解决这个问题,Polars 实现了一种非常强大的语法,在其延迟执行API和即时执行API上都有定义。
Polars Expressions
刚才我们提到自定义 Python 函数会损伤并行能力,Polars 提供了惰性 API 来应对这种情况。接下来
我们看看这是什么意思。
我们可以从这个数据集开始:US congress dataset.
import polars as pl
from .dataset import dataset
q = (
dataset.lazy()
.groupby("first_name")
.agg(
[
pl.count(),
pl.col("gender"),
pl.first("last_name"),
]
)
.sort("count", descending=True)
.limit(5)
)
df = q.collect()
基本聚合操作
你可以轻松地把多个聚合表达式放在一个 list 里面,并没有数量限制,你可以任意组合你放入任何数量的表达式。
下面这段代码中我们做如下聚合操作:
对于每一个 first_name 分组:
- 统计每组的行数:
- 短版:
pl.count("party") - 长版:
pl.col("party").count()
- 短版:
- 把每组的性别放入一个列表:
- 长版:
pl.col("gender").list()
- 长版:
- 找到每组的第一个
last_name:- 短版:
pl.first("last_name") - 长版:
pl.col("last_name").first()
- 短版:
除了聚合,我们还立即对结果进行排序,并取其中前5条记录,这样我们能更好地从宏观角度理解这组数据的特征。
import polars as pl
from .dataset import dataset
q = (
dataset.lazy()
.groupby("first_name")
.agg(
[
pl.count(),
pl.col("gender"),
pl.first("last_name"),
]
)
.sort("count", descending=True)
.limit(5)
)
df = q.collect()
shape: (5, 4)
┌────────────┬───────┬───────────────────┬───────────┐
│ first_name ┆ count ┆ gender ┆ last_name │
│ --- ┆ --- ┆ --- ┆ --- │
│ cat ┆ u32 ┆ list[cat] ┆ str │
╞════════════╪═══════╪═══════════════════╪═══════════╡
│ John ┆ 1256 ┆ ["M", "M", … "M"] ┆ Walker │
│ William ┆ 1022 ┆ ["M", "M", … "M"] ┆ Few │
│ James ┆ 714 ┆ ["M", "M", … "M"] ┆ Armstrong │
│ Thomas ┆ 454 ┆ ["M", "M", … "M"] ┆ Tucker │
│ Charles ┆ 439 ┆ ["M", "M", … "M"] ┆ Carroll │
└────────────┴───────┴───────────────────┴───────────┘
条件
简单吧!我们加点料!假设我们想要知道对于每个 state 有多少 Pro 和 Anti。我们可以
不用 lambda 而直接查询。
import polars as pl
from .dataset import dataset
q = (
dataset.lazy()
.groupby("state")
.agg(
[
(pl.col("party") == "Anti-Administration").sum().alias("anti"),
(pl.col("party") == "Pro-Administration").sum().alias("pro"),
]
)
.sort("pro", descending=True)
.limit(5)
)
df = q.collect()
shape: (5, 3)
┌───────┬──────┬─────┐
│ state ┆ anti ┆ pro │
│ --- ┆ --- ┆ --- │
│ cat ┆ u32 ┆ u32 │
╞═══════╪══════╪═════╡
│ NJ ┆ 0 ┆ 3 │
│ CT ┆ 0 ┆ 3 │
│ NC ┆ 1 ┆ 2 │
│ VA ┆ 3 ┆ 1 │
│ MA ┆ 0 ┆ 1 │
└───────┴──────┴─────┘
类似的,我们可以通过多层聚合实现,但是这不利于我显摆这些很酷的特征😉!
import polars as pl
from .dataset import dataset
q = (
dataset.lazy()
.groupby(["state", "party"])
.agg([pl.count("party").alias("count")])
.filter((pl.col("party") == "Anti-Administration") | (pl.col("party") == "Pro-Administration"))
.sort("count", descending=True)
.limit(5)
)
df = q.collect()
shape: (5, 3)
┌───────┬─────────────────────┬───────┐
│ state ┆ party ┆ count │
│ --- ┆ --- ┆ --- │
│ cat ┆ cat ┆ u32 │
╞═══════╪═════════════════════╪═══════╡
│ VA ┆ Anti-Administration ┆ 3 │
│ CT ┆ Pro-Administration ┆ 3 │
│ NJ ┆ Pro-Administration ┆ 3 │
│ NC ┆ Pro-Administration ┆ 2 │
│ VA ┆ Pro-Administration ┆ 1 │
└───────┴─────────────────────┴───────┘
过滤
我们也可以过滤分组。假设我们想要计算每组的均值,但是我们不希望计算所有值的均值,我们也不希望直接
从 DataFrame 过滤,因为我们后需还需要那些行做其他操作。
下面的例子说明我们是如何做到的。注意,我们可以写明 Python 的自定义函数,这些函数没有什么
运行时开销。因为这些函数返回了 Polars 表达式,我们并没在运行时让 Series 调用自动函数。
from datetime import date
import polars as pl
from .dataset import dataset
def compute_age() -> pl.Expr:
return date(2021, 1, 1).year - pl.col("birthday").dt.year()
def avg_birthday(gender: str) -> pl.Expr:
return compute_age().filter(pl.col("gender") == gender).mean().alias(f"avg {gender} birthday")
q = (
dataset.lazy()
.groupby(["state"])
.agg(
[
avg_birthday("M"),
avg_birthday("F"),
(pl.col("gender") == "M").sum().alias("# male"),
(pl.col("gender") == "F").sum().alias("# female"),
]
)
.limit(5)
)
df = q.collect()
shape: (5, 5)
┌───────┬────────────────┬────────────────┬────────┬──────────┐
│ state ┆ avg M birthday ┆ avg F birthday ┆ # male ┆ # female │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ cat ┆ f64 ┆ f64 ┆ u32 ┆ u32 │
╞═══════╪════════════════╪════════════════╪════════╪══════════╡
│ WI ┆ 152.939698 ┆ null ┆ 199 ┆ 0 │
│ LA ┆ 157.195531 ┆ 97.8 ┆ 194 ┆ 5 │
│ OH ┆ 171.836735 ┆ 79.444444 ┆ 672 ┆ 9 │
│ MO ┆ 163.741433 ┆ 81.625 ┆ 329 ┆ 8 │
│ PA ┆ 179.724846 ┆ 91.857143 ┆ 1050 ┆ 7 │
└───────┴────────────────┴────────────────┴────────┴──────────┘
排序
我们经常把一个 DataFrame 排序为了在分组操作的时候保持某种顺序。假设我们我们希望知道
每个 state 政治家的名字,并按照年龄排序。我们可以用 sort 和 groupby:
import polars as pl
from .dataset import dataset
def get_person() -> pl.Expr:
return pl.col("first_name") + pl.lit(" ") + pl.col("last_name")
q = (
dataset.lazy()
.sort("birthday", descending=True)
.groupby(["state"])
.agg(
[
get_person().first().alias("youngest"),
get_person().last().alias("oldest"),
]
)
.limit(5)
)
df = q.collect()
shape: (5, 3)
┌───────┬──────────────────┬─────────────────┐
│ state ┆ youngest ┆ oldest │
│ --- ┆ --- ┆ --- │
│ cat ┆ str ┆ str │
╞═══════╪══════════════════╪═════════════════╡
│ VT ┆ Benjamin Deming ┆ Moses Robinson │
│ MT ┆ Greg Gianforte ┆ James Cavanaugh │
│ MN ┆ Erik Paulsen ┆ Cyrus Aldrich │
│ AS ┆ Eni Faleomavaega ┆ Fofó Sunia │
│ NC ┆ James McKay ┆ Samuel Johnston │
└───────┴──────────────────┴─────────────────┘
但是,如果我们想把名字也按照字母排序,上面的代码就不行了。
幸运的是,我们可以在 groupby 上下文中进行排序,与 DataFrame 无关。
import polars as pl
from .dataset import dataset
def get_person() -> pl.Expr:
return pl.col("first_name") + pl.lit(" ") + pl.col("last_name")
q = (
dataset.lazy()
.sort("birthday", descending=True)
.groupby(["state"])
.agg(
[
get_person().first().alias("youngest"),
get_person().last().alias("oldest"),
get_person().sort().first().alias("alphabetical_first"),
]
)
.limit(5)
)
df = q.collect()
shape: (5, 4)
┌───────┬─────────────────────┬─────────────────┬────────────────────┐
│ state ┆ youngest ┆ oldest ┆ alphabetical_first │
│ --- ┆ --- ┆ --- ┆ --- │
│ cat ┆ str ┆ str ┆ str │
╞═══════╪═════════════════════╪═════════════════╪════════════════════╡
│ OH ┆ Amos Townsend ┆ Paul Fearing ┆ Aaron Harlan │
│ KY ┆ Benjamin Grey ┆ Matthew Lyon ┆ Aaron Harding │
│ HI ┆ Tulsi Gabbard ┆ Robert Wilcox ┆ Cecil Heftel │
│ LA ┆ John Slidell ┆ Thomas Posey ┆ Adolph Meyer │
│ PR ┆ Aníbal Acevedo-Vilá ┆ Tulio Larrinaga ┆ Antonio Colorado │
└───────┴─────────────────────┴─────────────────┴────────────────────┘
我们甚至可以在 groupby 上下文中增加另一个列,并且按照男女排序:
pl.col("gender").sort_by("first_name").first().alias("gender")
import polars as pl
from .dataset import dataset
def get_person() -> pl.Expr:
return pl.col("first_name") + pl.lit(" ") + pl.col("last_name")
q = (
dataset.lazy()
.sort("birthday", descending=True)
.groupby(["state"])
.agg(
[
get_person().first().alias("youngest"),
get_person().last().alias("oldest"),
get_person().sort().first().alias("alphabetical_first"),
pl.col("gender").sort_by("first_name").first().alias("gender"),
]
)
.sort("state")
.limit(5)
)
df = q.collect()
shape: (5, 5)
┌───────┬────────────────┬─────────────────┬────────────────────┬────────┐
│ state ┆ youngest ┆ oldest ┆ alphabetical_first ┆ gender │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ cat ┆ str ┆ str ┆ str ┆ cat │
╞═══════╪════════════════╪═════════════════╪════════════════════╪════════╡
│ CT ┆ Samuel Simons ┆ Roger Sherman ┆ Abner Sibal ┆ M │
│ KY ┆ Benjamin Grey ┆ Matthew Lyon ┆ Aaron Harding ┆ M │
│ FL ┆ George Hawkins ┆ Joseph White ┆ Abijah Gilbert ┆ M │
│ NY ┆ Robert Baker ┆ Philip Schuyler ┆ A. Foster ┆ M │
│ MI ┆ Samuel Clark ┆ Gabriel Richard ┆ Aaron Bliss ┆ M │
└───────┴────────────────┴─────────────────┴────────────────────┴────────┘
结论
上面的例子中我们知道通过组合表达式可以完成复杂的查询。而且,我们避免了使用自定义 Python 函数
带来的性能损失 (解释器和 GIL)。
如果这里少了哪类表达式,清在这里开一个 Issue: feature request!
折叠
Polars 提供了横向表达式或者方法,比如sum,
min, mean 等等,
我们只需要设置 axis=1 即可实现横向聚合。但是,当我们需要复杂的聚合模式时,Polars 提供的基本函数可能不能胜任,这时候我们需要 fold 函数。
fold 函数在列方向的性能最佳,它很好的利用了数据的内存格局,通常还会伴随向量化操作。
让我们通过里一个例子看看如何受使用 fold 实现 sum 函数。
手工 sum
{
"a": [1, 2, 3],
"b": [10, 20, 30],
}
)
out = df.select(
pl.fold(acc=pl.lit(0), function=lambda acc, x: acc + x, exprs=pl.col("*")).alias("sum"),
)
print(out)
shape: (3, 1)
┌─────┐
│ sum │
│ --- │
│ i64 │
╞═════╡
│ 11 │
│ 22 │
│ 33 │
└─────┘
上面的例子中,函数 f(acc, x) -> acc 被反复调用并把结果累加到 acc 变量,最终把结果放入 x 列。
这个函数按照列执行,并且充分利用了缓存和向量化操作。
条件语句
当我们希望对一个 DataFrame 的所有列是施加条件语句的时候,采用 fold 就非常简洁。
{
"a": [1, 2, 3],
"b": [0, 1, 2],
}
)
out = df.filter(
pl.fold(
acc=pl.lit(True),
function=lambda acc, x: acc & x,
exprs=pl.col("*") > 1,
)
)
print(out)
shape: (1, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═════╪═════╡
│ 3 ┆ 2 │
└─────┴─────┘
上面的例子中,我们选择所有行,这些行的每一列都大于 1。
fold 和 字符串数据
Fold 可以用来连接字符串。但是由于这个操作会产生一些中间结果,这个操作是 O(n^2) 的时间复杂度。
因此,我们推荐使用 concat_str 表达式。
df = pl.DataFrame(
{
"a": ["a", "b", "c"],
"b": [1, 2, 3],
}
)
out = df.select(
[
pl.concat_str(["a", "b"]),
]
)
print(out)
shape: (3, 1)
┌─────┐
│ a │
│ --- │
│ str │
╞═════╡
│ a1 │
│ b2 │
│ c3 │
└─────┘
自定义函数
现在你应该相信,polar表达式是如此的强大和灵活,以至于对自定义python函数的需求比你在其他库中可能需要的要少得多。
尽管如此,你仍然需要有能力将表达式传递给第三方库,或者将你的黑匣子函数应用于polar数据。
为此,我们提供了以下几种表达式:
mapapply
map
在操作方式上和最终向用户传递的数据上,map和apply函数有重要的区别。
map函数将表达式所支持的Series数据原封不动的传递。
map函数在select和groupby中遵循相同的规则,这将意味着Series代表DataFrame中的一个列。注意,在groupby情况下,该列还没有被分组!
map函数的用法是将表达式中的Series传递给第三方库。下面我们展示了如何使用map将一个表达式列传递给神经网络模型。
df.with_column([
pl.col("features").map(lambda s: MyNeuralNetwork.forward(s.to_numpy())).alias("activations")
])
在groupby中,map的使用情况很有限。它们只用于性能方面,但很容易导致不正确的结果。让我们来解释一下原因。
df = pl.DataFrame(
{
"keys": ["a", "a", "b"],
"values": [10, 7, 1],
}
)
out = df.groupby("keys", maintain_order=True).agg(
[
pl.col("values").map(lambda s: s.shift()).alias("shift_map"),
pl.col("values").shift().alias("shift_expression"),
]
)
print(df)
shape: (3, 2)
┌──────┬────────┐
│ keys ┆ values │
│ --- ┆ --- │
│ str ┆ i64 │
╞══════╪════════╡
│ a ┆ 10 │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ a ┆ 7 │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ b ┆ 1 │
└──────┴────────┘
在上面的片段中,我们按"keys"列分组。这意味着我们有以下几个组。
"a" -> [10, 7]
"b" -> [1]
如果我们再向右应用一个shift操作,我们就会发现。
"a" -> [null, 10]
"b" -> [null]
现在,让我们打印一下得到的结果:
print(out)
shape: (2, 3)
┌──────┬────────────┬──────────────────┐
│ keys ┆ shift_map ┆ shift_expression │
│ --- ┆ --- ┆ --- │
│ str ┆ list[i64] ┆ list[i64] │
╞══════╪════════════╪══════════════════╡
│ a ┆ [null, 10] ┆ [null, 10] │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ b ┆ [7] ┆ [null] │
└──────┴────────────┴──────────────────┘
😯.. 很明显,我们得到了一个错误答案。"b"组甚至从"a"组拿到了一个值7😵.
这是一个可怕的错误,因为map在我们聚合之前就应用了这个函数!这意味着整个列[10, 7, 1]先向右移向到了[null, 10, 7],然后再被聚合。
所以我们的建议是,除非你知道你需要使用map并且知道你在做什么,否则永远不要在groupby时使用map。
apply
幸运的是,我们可以用apply来解决之前的例子。apply可以对该操作的最小的逻辑元素起作用。
这就意味着:
select-> 单个元素groupby-> 单个分组
因此,我们可以用apply来解决我们上述的问题:
out = df.groupby("keys", maintain_order=True).agg(
[
pl.col("values").apply(lambda s: s.shift()).alias("shift_map"),
pl.col("values").shift().alias("shift_expression"),
]
)
print(out)
shape: (2, 3)
┌──────┬────────────┬──────────────────┐
│ keys ┆ shift_map ┆ shift_expression │
│ --- ┆ --- ┆ --- │
│ str ┆ list[i64] ┆ list[i64] │
╞══════╪════════════╪══════════════════╡
│ a ┆ [null, 10] ┆ [null, 10] │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ b ┆ [null] ┆ [null] │
└──────┴────────────┴──────────────────┘
可以看到,我们得到了正确的结果! 🎉
select中的apply
在select中,apply表达式将列的元素传递给python函数。
注意,你现在正在运行Python,这将会很慢。
让我们通过一些例子来看看会发生什么。我们将继续使用我们在本节开始时定义的DataFrame,并展示一个使用apply函数的例子和一个使用表达式API实现相同目标的反例。
添加一个计数器
在这个例子中,我们创建了一个全局的 counter (计数器),然后在每处理一个元素时将整数 1 添加到全局状态中。每个迭代的增量结果将被添加到元素值中。
counter = 0
def add_counter(val: int) -> int:
global counter
counter += 1
return counter + val
out = df.select(
[
pl.col("values").apply(add_counter).alias("solution_apply"),
(pl.col("values") + pl.arange(1, pl.count() + 1)).alias("solution_expr"),
]
)
print(out)
shape: (3, 2)
┌────────────────┬───────────────┐
│ solution_apply ┆ solution_expr │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞════════════════╪═══════════════╡
│ 11 ┆ 11 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 9 ┆ 9 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 4 ┆ 4 │
└────────────────┴───────────────┘
合并多列值
如果我们想在一次apply函数调用中访问不同列的值,我们可以创建struct数据类型。这种数据类型将这些列作为字段收集在struct中。因此,如果我们从列"keys"和"values"中创建一个struct,我们会得到以下结构元素。
[
{"keys": "a", "values": 10},
{"keys": "a", "values": 7},
{"keys": "b", "values": 1},
]
这些将作为dict传递给调用的Python函数,因此可以通过field: str进行索引。
out = df.select(
[
pl.struct(["keys", "values"]).apply(lambda x: len(x["keys"]) + x["values"]).alias("solution_apply"),
(pl.col("keys").str.lengths() + pl.col("values")).alias("solution_expr"),
]
)
print(out)
shape: (3, 2)
┌────────────────┬───────────────┐
│ solution_apply ┆ solution_expr │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞════════════════╪═══════════════╡
│ 11 ┆ 11 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 8 ┆ 8 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2 ┆ 2 │
└────────────────┴───────────────┘
返回类型
自定义Python函数对polar而言是黑箱。我们真的不知道你在做什么黑科技,所以我们不得不推断并尽力去理解你的意思。
数据类型是自动推断出来的。我们通过等待第一个非空值来做到这一点。这个值将被用来确定Series的类型。
python类型与polars数据类型的映射如下:
int->Int64float->Float64bool->Booleanstr->Utf8list[tp]->List[tp](其中内部类型的推断规则相同)dict[str, [tp]]->structAny->object(在任何时候都要防止这种情况)
作为一个用户,我们希望您能了解我们的工作,以便能更好地利用自定义函数。
窗口函数 🚀🚀
窗口函数是一种强大的表达式。它可以让用户在 select 上下文中分组进行类聚。
让我们通过例子看看这是什么意思。首先,我们创建一个数据结构,这个数据包含如下列,分别代表口袋妖怪的一些信息:
['#', 'Name', 'Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary']
import polars as pl
# 然后,让我们加载一些包pokemon信息的csv数据
df = pl.read_csv(
"https://gist.githubusercontent.com/ritchie46/cac6b337ea52281aa23c049250a4ff03/raw/89a957ff3919d90e6ef2d34235e6bf22304f3366/pokemon.csv"
)
shape: (163, 13)
┌─────┬───────────────────────┬─────────┬────────┬───┬─────────┬───────┬────────────┬───────────┐
│ # ┆ Name ┆ Type 1 ┆ Type 2 ┆ … ┆ Sp. Def ┆ Speed ┆ Generation ┆ Legendary │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ bool │
╞═════╪═══════════════════════╪═════════╪════════╪═══╪═════════╪═══════╪════════════╪═══════════╡
│ 1 ┆ Bulbasaur ┆ Grass ┆ Poison ┆ … ┆ 65 ┆ 45 ┆ 1 ┆ false │
│ 2 ┆ Ivysaur ┆ Grass ┆ Poison ┆ … ┆ 80 ┆ 60 ┆ 1 ┆ false │
│ 3 ┆ Venusaur ┆ Grass ┆ Poison ┆ … ┆ 100 ┆ 80 ┆ 1 ┆ false │
│ 3 ┆ VenusaurMega Venusaur ┆ Grass ┆ Poison ┆ … ┆ 120 ┆ 80 ┆ 1 ┆ false │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 147 ┆ Dratini ┆ Dragon ┆ null ┆ … ┆ 50 ┆ 50 ┆ 1 ┆ false │
│ 148 ┆ Dragonair ┆ Dragon ┆ null ┆ … ┆ 70 ┆ 70 ┆ 1 ┆ false │
│ 149 ┆ Dragonite ┆ Dragon ┆ Flying ┆ … ┆ 100 ┆ 80 ┆ 1 ┆ false │
│ 150 ┆ Mewtwo ┆ Psychic ┆ null ┆ … ┆ 90 ┆ 130 ┆ 1 ┆ true │
└─────┴───────────────────────┴─────────┴────────┴───┴─────────┴───────┴────────────┴───────────┘
Groupby 类聚
下面我们看看如何用窗口函数对不同的列分组并且类聚。这样我们可以在一次查询中并行的运行多个分组操作。
类聚的结果会投射会原有的行。因此,窗口函数永远返回一个跟原有 DataFrame 一样规格的 DataFrame。
注意,我们使用了 .over("Type 1") 和 .over(["Type 1", "Type 2"]),利用窗口函数我们可以一个
select 语境中实现多个分组类聚。
更好的是,计算过的分组会被缓存并且在不同的窗口函数中共享。
out = df.select(
[
"Type 1",
"Type 2",
pl.col("Attack").mean().over("Type 1").alias("avg_attack_by_type"),
pl.col("Defense").mean().over(["Type 1", "Type 2"]).alias("avg_defense_by_type_combination"),
pl.col("Attack").mean().alias("avg_attack"),
]
)
shape: (163, 5)
┌─────────┬────────┬────────────────────┬─────────────────────────────────┬────────────┐
│ Type 1 ┆ Type 2 ┆ avg_attack_by_type ┆ avg_defense_by_type_combination ┆ avg_attack │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ f64 ┆ f64 ┆ f64 │
╞═════════╪════════╪════════════════════╪═════════════════════════════════╪════════════╡
│ Grass ┆ Poison ┆ 72.923077 ┆ 67.8 ┆ 75.349693 │
│ Grass ┆ Poison ┆ 72.923077 ┆ 67.8 ┆ 75.349693 │
│ Grass ┆ Poison ┆ 72.923077 ┆ 67.8 ┆ 75.349693 │
│ Grass ┆ Poison ┆ 72.923077 ┆ 67.8 ┆ 75.349693 │
│ … ┆ … ┆ … ┆ … ┆ … │
│ Dragon ┆ null ┆ 94.0 ┆ 55.0 ┆ 75.349693 │
│ Dragon ┆ null ┆ 94.0 ┆ 55.0 ┆ 75.349693 │
│ Dragon ┆ Flying ┆ 94.0 ┆ 95.0 ┆ 75.349693 │
│ Psychic ┆ null ┆ 53.875 ┆ 51.428571 ┆ 75.349693 │
└─────────┴────────┴────────────────────┴─────────────────────────────────┴────────────┘
分组操作
窗口函数不仅仅可以类聚,还可以用来按照组施加自定义函数。例如,如果你想要在某一组中排序,你可以:
.col("value").sort().over("group")。
让我们试着过滤一些行:
filtered = df.filter(pl.col("Type 2") == "Psychic").select(
[
"Name",
"Type 1",
"Speed",
]
)
print(filtered)
shape: (7, 3)
┌─────────────────────┬────────┬───────┐
│ Name ┆ Type 1 ┆ Speed │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ i64 │
╞═════════════════════╪════════╪═══════╡
│ Slowpoke ┆ Water ┆ 15 │
│ Slowbro ┆ Water ┆ 30 │
│ SlowbroMega Slowbro ┆ Water ┆ 30 │
│ Exeggcute ┆ Grass ┆ 40 │
│ Exeggutor ┆ Grass ┆ 55 │
│ Starmie ┆ Water ┆ 115 │
│ Jynx ┆ Ice ┆ 95 │
└─────────────────────┴────────┴───────┘
注意到,分组 Water 的列 Type 1 并不连续,中间有两行 Grass。而且,同组中的每一个口袋妖股
被按照 Speed 升序排列。不幸的是,这个例子我们希望降序排列,幸运的是,这很简单:
out = filtered.with_columns(
[
pl.col(["Name", "Speed"]).sort(descending=True).over("Type 1"),
]
)
print(out)
shape: (7, 3)
┌─────────────────────┬────────┬───────┐
│ Name ┆ Type 1 ┆ Speed │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ i64 │
╞═════════════════════╪════════╪═══════╡
│ Starmie ┆ Water ┆ 115 │
│ Slowpoke ┆ Water ┆ 30 │
│ SlowbroMega Slowbro ┆ Water ┆ 30 │
│ Exeggutor ┆ Grass ┆ 55 │
│ Exeggcute ┆ Grass ┆ 40 │
│ Slowbro ┆ Water ┆ 15 │
│ Jynx ┆ Ice ┆ 95 │
└─────────────────────┴────────┴───────┘
Polars 会追踪每个组的位置,并把相应的表达式映射到适当的行。这个操作可以在一个 select 环境中完成。
窗口函数的强大之处在于:你通常不需要 groupby -> explode 组合,而是把逻辑放入一个表达式中。
这也使得 API 更加简洁:
groupby-> 标记类聚的分组,返回一个跟组的个数一致的DataFrameover-> 标记我们希望对这个分组进行计算,但是不会更改原有DataFrame的形状
窗口表达式的规则
窗口表达式的计算规则如下(假设我们有一个 pl.Int32 列):
# 分组内类聚且广播
# 输出类型: -> Int32
pl.sum("foo").over("groups")
# 组内加和,然后乘以组内的元素
# 输出类型: -> Int32
(pl.col("x").sum() * pl.col("y")).over("groups")
# 组内加和,然后乘以组内的元素
# 并且组内类聚成一个列表
# 输出类型: -> List(Int32)
(pl.col("x").sum() * pl.col("y")).list().over("groups")
# 注意这里需要一个显式的 `list` 调用
# 组内加和,然后乘以组内的元素
# 并且组内类聚成一个列表
# list() 会展开
# 如果组内是有序的,这是最快的操作方法:
(pl.col("x").sum() * pl.col("y")).list().over("groups").flatten()
展开窗口函数
就像刚刚的例子,如果你的窗口函数返回一个 list:
pl.col("Name").sort_by(pl.col("Speed")).head(3).list().over("Type 1")
这样可以,但是这样会返回一个类型为 List 的列,这可能不是我们想要的,而且会增加内存使用。
这是我们可以采用 flatten。这个函数会把一个 2D 列表转换成 1D,然后把列投射到我们的 DataFrame。
这个操作非常快,因为 reshape 基本没有成本,给原有 DataFrame 增加列也非常快,因为我们不需要
一般窗口函数的联合(Join)操作。
但是,想要正确的使用这个操作,我们要保证用于 over 的列是有序的。
与 Numpy 交互
Polars 表达式支持NumPy ufuncs。 这里查看所有受支持的numpy函数的列表。
这意味着,如果一个函数不是由Polars提供的,我们可以使用NumPy,我们仍然可以通过NumPyAPI进行快速的列操作。
实例
import polars as pl
import numpy as np
df = pl.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
out = df.select(
[
np.log(pl.all()).suffix("_log"), # 对df所有列求对数
]
)
print(out)
shape: (3, 2)
┌──────────┬──────────┐
│ a_log ┆ b_log │
│ --- ┆ --- │
│ f64 ┆ f64 │
╞══════════╪══════════╡
│ 0.0 ┆ 1.386294 │
│ 0.693147 ┆ 1.609438 │
│ 1.098612 ┆ 1.791759 │
└──────────┴──────────┘
Gotcha's
阅读更多关于 gotcha's 这里.
实例
表达式方法
可以在Expr上找到可能的表达式的完整列表,参考指南中的定义。
视频介绍
你不喜欢阅读文档吗?看看这段关于Polars及其表达的介绍视频。
索引
Polars DataFrame没有索引,因此索引行为可以是一致的,而不需要 df.loc,
df.iloc, or a df.at 操作。
规则如下(取决于值的数据类型):
-
数值型
- axis 0: 行(row)
- axis 1: 列(column)
-
数值型 + 字符串
- axis 0: 行(这里只接收数字)
- axis 1: 列(接受数字+字符串值)
-
仅字符串
- axis 0: 列(column)
- axis 1: 报错(error)
-
表达式
所有表达式求值都是并行执行的
- axis 0: 列(column)
- axis 1: 列(column)
- ..
- axis n: 列(column)
与Pandas的对比
| pandas | polars |
|---|---|
选择列df.iloc[2] | df[2, :] |
按索引选择几行df.iloc[[2, 5, 6]] | df[[2, 5, 6], :] |
选择行的切片df.iloc[2:6] | df[2:6, :] |
使用布尔掩码(boolean mask)选择行df.iloc[True, True, False] | df[[True, True, False]] |
按谓词(predicate)条件选择行df.loc[df["A"] > 3] | df[df["A"] > 3] |
选择列的切片df.iloc[:, 1:3] | df[:, 1:3] |
按字符串顺序选择列的切片df.loc[:, "A":"Z"] | df[:, "A":"Z"] |
选择单个值(标量)df.loc[2, "A"] | df[2, "A"] |
选择单个值(标量)df.iloc[2, 1] | df[2, 1] |
选择单个值(Series或DataFrame)df.loc[2, ["A"]] | df[2, ["A"]] |
选择单个值 (Series或DataFrame)df.iloc[2, [1]] | df[2, [1]] |
表达式
表达式也可以用于索引(它是df.select的语法糖)。
这可以用来做一些很有别致的选择。
df[[
pl.col("A").head(5), # 从“A”的首部开始获取
pl.col("B").tail(5).reverse(), # 以逆序的方式获取“B”的后部
pl.col("B").filter(pl.col("B") > 5).head(5), # 首先得到满足谓词的“B”
pl.sum("A").over("B").head(5) # 获取“A”在“B”组上的总和,并返回前5个
数据类型
Polars完全基于Arrow数据类型,并由Arrow内存阵列支持。这使得数据处理缓存效率高,支持进程间通信。大多数数据类型遵循确切的实现来自Arrow,除了Utf8(实际上是LargeUtf8)、category和Object(支持有限)。
这些数据类型是:
Int8: 8位有符号整数。Int16: 16位有符号整数。Int32: 32位有符号整数。Int64: 64位有符号整数。UInt8: 8位有符号整数。UInt16: 16位无符号整数。UInt32: 32位无符号整数。UInt64: 64位无符号整数。Float32: 32位浮点数。Float64: 64位浮点数。Boolean: 布尔型有效位压缩。Utf8: 字符串数据(内部实际上是ArrowLargeUtf8)。List: 列表数组包含着包含列表值的子数组和偏移数组。(这实际上是内部的ArrowLargeList)。Date: 日期表示,内部表示为自UNIX纪元以来的天数,由32位有符号整数编码。Datetime: Datetime表示法,内部表示为自UNIX纪元以来的纳秒,由64位有符号整数编码。Duration: 时间型。在减去Date/Datetime时创建。Time: 时间表示法,从午夜开始在内部表示为纳秒。Object: 受支持的有限数据类型,可以是任何值。
要了解有关这些数据类型的内部表示形式的更多信息,请查看Arrow柱状格式。
来自 Pandas
如果你很熟悉Pandas,那么你只需要知道一件事:
polars != pandas
如果你的Polars代码写起来很像Pandas,程序也许可以运行,但是很有可能会慢于它本该有的速度。
下面我们就通过几段经典Pandas代码来对比同样功能的Polars代码。
列运算
Pandas
# 以下代码是顺序执行的
df["a"] = df["b"] * 10
df["c"] = df["b"] * 100
Polars
# 以下代码是并发执行的
df.with_columns([
(pl.col("b") * 10).alias("a"),
(pl.col("b") * 100).alias("c"),
])
基于判定的列运算
Pandas
df.loc[df["c"] == 2, "a"] = df.loc[df["c"] == 2, "b"]
Polars
df.with_column(
pl.when(pl.col("c") == 2)
.then(pl.col("b"))
.otherwise(pl.col("a")).alias("a")
)
注意,Polars的方式更“干净”,因而原始DataFrame中的数据并没有被修改。并且,mask(掩膜)也不像在Pandas中那样被计算了两次。
当然,你可以在Pandas中防止原始DataFrame中的数据在这一步被修改,但这需要借助临时变量。
另外,Polars能并行计算每一个 if -> then -> otherwise的分支。当分支的计算复杂度提高时,就能体现并行计算的优势了。
筛选
Pandas
df.loc[(df['sqft_living'] > 2500) & (df['price'] < 300000)]
Polars
df.filter(
(pl.col("m2_living") > 2500) & (pl.col("price") < 300000)
)
PS: 这部分内容还在建设中,内容有缺少?欢迎提交PR!
没有索引列
根本不需要索引列!没有索引列会让处理变得更简单。如果你不相信来说服我们吧!
Pandas重塑
在Pandas文档中演示了一种聚合操作 transform(重塑):
Pandas
df = pd.DataFrame({
"c": [1, 1, 1, 2, 2, 2, 2],
"type": ["m", "n", "o", "m", "m", "n", "n"]
})
df["size"] = df.groupby("c")["type"].transform(len)
使用Pandas 要先聚合"c"列、截取出"type"列、计算组的长度,最后将结果拼接回原始DataFrame中。
其结果是:
c type size
0 1 m 3
1 1 n 3
2 1 o 3
3 2 m 4
4 2 m 4
5 2 n 4
6 2 n 4
Polars
在 Polars中可以用 窗口 函数来达到相同的目的。
df.select([
pl.all(),
pl.col("type").count().over("c").alias("size")
])
shape: (7, 3)
┌─────┬──────┬──────┐
│ c ┆ type ┆ size │
│ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ u32 │
╞═════╪══════╪══════╡
│ 1 ┆ m ┆ 3 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ 1 ┆ n ┆ 3 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ 1 ┆ o ┆ 3 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ 2 ┆ m ┆ 4 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ 2 ┆ m ┆ 4 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ 2 ┆ n ┆ 4 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ 2 ┆ n ┆ 4 │
└─────┴──────┴──────┘
因为我们可以将所有的操作放在一个语句中,因此结合多个窗口函数,甚至结合不同的组都是可以的!
Polars会将应用于相同组的窗口函数表达式缓存,所以将多个表达式入在一个select语句中既方便且优雅。
例如:
df.select([
pl.all(),
pl.col("c").count().over("c").alias("size"),
pl.col("c").sum().over("type").alias("sum"),
pl.col("c").reverse().over("c").flatten().alias("reverse_type")
])
shape: (7, 5)
┌─────┬──────┬──────┬─────┬──────────────┐
│ c ┆ type ┆ size ┆ sum ┆ reverse_type │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ u32 ┆ i64 ┆ i64 │
╞═════╪══════╪══════╪═════╪══════════════╡
│ 1 ┆ m ┆ 3 ┆ 5 ┆ 2 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 1 ┆ n ┆ 3 ┆ 5 ┆ 2 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 1 ┆ o ┆ 3 ┆ 1 ┆ 2 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2 ┆ m ┆ 4 ┆ 5 ┆ 2 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2 ┆ m ┆ 4 ┆ 5 ┆ 1 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2 ┆ n ┆ 4 ┆ 5 ┆ 1 │
├╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2 ┆ n ┆ 4 ┆ 5 ┆ 1 │
└─────┴──────┴──────┴─────┴──────────────┘
来自 Apache Spark
基于列的方法 vs. 基于行的方法
Spark DataFrame 类似于一个行的集合,而 Polars DataFrame 更接近于一个列的集合。这意味着你可以在 Polars 中以 Spark 中不可能的方式组合列,因为 Spark 保留了每一行中的数据关系。
考虑下面这个样本数据集。
import polars as pl
df = pl.DataFrame({
"foo": ["a", "b", "c", "d", "d"],
"bar": [1, 2, 3, 4, 5],
})
dfs = spark.createDataFrame(
[
("a", 1),
("b", 2),
("c", 3),
("d", 4),
("d", 5),
],
schema=["foo", "bar"],
)
案例 1: 合并 head 与 sum
在 Polars 中你可以写出下面的语句:
df.select([
pl.col("foo").sort().head(2),
pl.col("bar").filter(pl.col("foo") == "d").sum()
])
该代码段输出:
shape: (2, 2)
┌─────┬─────┐
│ foo ┆ bar │
│ --- ┆ --- │
│ str ┆ i64 │
╞═════╪═════╡
│ a ┆ 9 │
├╌╌╌╌╌┼╌╌╌╌╌┤
│ b ┆ 9 │
└─────┴─────┘
列 foo 和 bar 上的表达式是完全独立的。由于 bar 上的表达式返回一个单一的值,这个值在 foo 表达式输出的每个值中都会重复,但是 a 和 b 与产生 9 没有关系。
要在 Spark 中做类似的事情,你需要单独计算总和,并将其作为字面值返回:
from pyspark.sql.functions import col, sum, lit
bar_sum = (
dfs
.where(col("foo") == "d")
.groupBy()
.agg(sum(col("bar")))
.take(1)[0][0]
)
(
dfs
.orderBy("foo")
.limit(2)
.withColumn("bar", lit(bar_sum))
.show()
)
该代码段输出:
+---+---+
|foo|bar|
+---+---+
| a| 9|
| b| 9|
+---+---+
案例 2: 合并两个 head
在 Polars 中你可以在同一个 DataFrame 上结合两个不同的 head 表达式,只要它们返回相同数量的值。
df.select([
pl.col("foo").sort().head(2),
pl.col("bar").sort(reverse=True).head(2),
])
该代码段输出:
shape: (3, 2)
┌─────┬─────┐
│ foo ┆ bar │
│ --- ┆ --- │
│ str ┆ i64 │
╞═════╪═════╡
│ a ┆ 5 │
├╌╌╌╌╌┼╌╌╌╌╌┤
│ b ┆ 4 │
└─────┴─────┘
同样,这里的两个 head 表达式是完全独立的,a 与 5 和 b 与 4 的配对纯粹是表达式输出的两列并列的结果。
为了在 Spark 中完成类似的工作,你需要生成一个人工的 key 使你能够以相同的方式连接这些值。
from pyspark.sql import Window
from pyspark.sql.functions import row_number
foo_dfs = (
dfs
.withColumn(
"rownum",
row_number().over(Window.orderBy("foo"))
)
)
bar_dfs = (
dfs
.withColumn(
"rownum",
row_number().over(Window.orderBy(col("bar").desc()))
)
)
(
foo_dfs.alias("foo")
.join(bar_dfs.alias("bar"), on="rownum")
.select("foo.foo", "bar.bar")
.limit(2)
.show()
)
该代码段输出:
+---+---+
|foo|bar|
+---+---+
| a| 5|
| b| 4|
+---+---+
时间序列
Polars 为时间序列重采样提供了强大的方法支持。许多人都知道 Pandas 中 df.resample 提供了重采样功能。
Polars 在以下两个方面与 Pandas 有所区别:
- 上采样 (Up Sampling)
- 下采样 (Down Sampling)
上采样 (Up Sampling)
上采样实际上相当于将一个日期范围与你的数据集进行左关联 (left join) 操作,并填充缺失数据。Polars 为此操作
提供了封装方法,你可以参考下面的一个示例。
df = pl.DataFrame(
{
"time": pl.date_range(start=datetime(2021, 12, 16), end=datetime(2021, 12, 16, 3), interval="30m", eager=True),
"groups": ["a", "a", "a", "b", "b", "a", "a"],
"values": [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0],
}
)
out1 = df.upsample(time_column="time", every="15m").fill_null(strategy="forward")
out2 = df.upsample(time_column="time", every="15m").interpolate().fill_null(strategy="forward")
下采样 (Down Sampling)
下采样很有意思。你需要处理日期间隔、窗口持续时间、聚合等问题。
Polars 将下采样视为分组(groupby)操作的一个特例,因此表达式 API 为分组(groupby)上下文(contexts)提供了两个额外的入口。
你可以通过调用二者其中任何一个函数来获取对表达式方法的完整访问,它有着强大的性能!
让我们通过下面几个示例来理解这样做的意义。
df = pl.DataFrame(
{
"time": pl.date_range(
start=datetime(2021, 12, 16),
end=datetime(2021, 12, 16, 3),
interval="30m",
eager=True,
),
"groups": ["a", "a", "a", "b", "b", "a", "a"],
}
)
out = df.groupby_dynamic(
"time",
every="1h",
closed="both",
by="groups",
include_boundaries=True,
).agg([pl.count()])
动态分组 (Groupby Dynamic)
在下面的一段代码中,我们以 天 ("1d") 为单位,把关于 2021 年的 日期范围 (date range) 创建为一个 DataFrame。
接下来,我们创建起始于每 月 ("1mo"),长度为 1 个月的动态窗口 (dynamic windows)。动态窗口的大小并不由 DataFrame
中的行数决定,而是由一个时间单位 (temporal unit) 决定,比如一天 ("1d"),三周 ("3w"),亦或是五纳秒 ("5ns") ...
希望这个例子有助于让你理解动态窗口的含义。
匹配某个动态窗口的值会被分配到该窗口所对应的组中,接下来你可以用强大的表达式方法进行聚合操作。
下面的示例使用 groupby_dynamic 来计算:
- 距离月底的天数
- 一个月里的天数
# 时间轴(从low到high,间隔为1天,轴名称为"time")
df = pl.date_range(start=datetime(2021, 1, 1),
end=datetime(2021, 12, 31),
interval="1d",
name="time",
eager=True).to_frame()
out = (
df.groupby_dynamic("time", every="1mo", period="1mo", closed="left")
.agg(
[
pl.col("time").cumcount().reverse().head(3).alias("day/eom"),
((pl.col("time") - pl.col("time").first()).last().dt.days() + 1).alias("days_in_month"),
]
)
.explode("day/eom")
)
print(out)
shape: (36, 3)
┌─────────────────────┬─────────┬───────────────┐
│ time ┆ day/eom ┆ days_in_month │
│ --- ┆ --- ┆ --- │
│ datetime[μs] ┆ u32 ┆ i64 │
╞═════════════════════╪═════════╪═══════════════╡
│ 2021-01-01 00:00:00 ┆ 30 ┆ 31 │
│ 2021-01-01 00:00:00 ┆ 29 ┆ 31 │
│ 2021-01-01 00:00:00 ┆ 28 ┆ 31 │
│ 2021-02-01 00:00:00 ┆ 27 ┆ 28 │
│ … ┆ … ┆ … │
│ 2021-11-01 00:00:00 ┆ 27 ┆ 30 │
│ 2021-12-01 00:00:00 ┆ 30 ┆ 31 │
│ 2021-12-01 00:00:00 ┆ 29 ┆ 31 │
│ 2021-12-01 00:00:00 ┆ 28 ┆ 31 │
└─────────────────────┴─────────┴───────────────┘
要定义一个动态窗口,需要提供以下三个参数:
- every:窗口的时间间隔
- period:窗口的持续时间
- offset:可以对窗口的开始进行偏移
因为 every 并不总是需要等于 period,我们可以用一种非常灵活的方式来创建很多组别。它们可以互相重叠,也可以在组间留出边界。
我们先从简单的例子开始 🥱 想想看下面几组参数会创建出怎么样的窗口。
- every: 1 天 ->
"1d" - period: 1 天 ->
"1d"
创建出的窗口相邻,且长度相等
|--|
|--|
|--|
- every: 1 天 ->
"1d" - period: 2 天 ->
"2d"
窗口之间有 1 天的重叠
|----|
|----|
|----|
- every: 2 天 ->
"2d" - period: 1 天 ->
"1d"
两个窗口之间留有间隔,在这段范围内的数据不属于任何一个组别
|--|
|--|
|--|
滚动分组 (Rolling Groupby)
滚动分组是分组(groupby)上下文的另一个入口。但与 groupby_dynamic 不同的是,窗口的设置不接受参数 every 和 period —— 对于一个滚动分组,窗口不是固定的!它们由 index_column 中的值决定。
想象一下,你有一个值为{2021-01-01, 20210-01-05} 的时间序列,使用参数 period="5d" 将创建以下窗口:
2021-01-01 2021-01-06
|----------|
2021-01-05 2021-01-10
|----------|
由于滚动分组的窗口总是由 DataFrame 列中的值决定,组别的数目总是与原 DataFrame 相等。
将动态分组与滚动分组结合起来
用正常的 groupby 操作,我们可以将这两种分组方式结合起来。
下面是一个使用动态分组的例子:
from datetime import datetime
import polars as pl
df = pl.DataFrame(
{
"time": pl.date_range(
start=datetime(2021, 12, 16),
end=datetime(2021, 12, 16, 3),
interval="30m",
eager=True,
),
"groups": ["a", "a", "a", "b", "b", "a", "a"],
}
)
print(out)
shape: (7, 2)
┌─────────────────────┬────────┐
│ time ┆ groups │
│ --- ┆ --- │
│ datetime[μs] ┆ str │
╞═════════════════════╪════════╡
│ 2021-12-16 00:00:00 ┆ a │
│ 2021-12-16 00:30:00 ┆ a │
│ 2021-12-16 01:00:00 ┆ a │
│ 2021-12-16 01:30:00 ┆ b │
│ 2021-12-16 02:00:00 ┆ b │
│ 2021-12-16 02:30:00 ┆ a │
│ 2021-12-16 03:00:00 ┆ a │
└─────────────────────┴────────┘
# 动态分组
out = df.groupby_dynamic(
"time",
every="1h",
closed="both",
by="groups",
include_boundaries=True,
).agg([pl.count()])
print(df)
shape: (7, 5)
┌────────┬─────────────────────┬─────────────────────┬─────────────────────┬───────┐
│ groups ┆ _lower_boundary ┆ _upper_boundary ┆ time ┆ count │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ datetime[μs] ┆ datetime[μs] ┆ datetime[μs] ┆ u32 │
╞════════╪═════════════════════╪═════════════════════╪═════════════════════╪═══════╡
│ a ┆ 2021-12-15 23:00:00 ┆ 2021-12-16 00:00:00 ┆ 2021-12-15 23:00:00 ┆ 1 │
│ a ┆ 2021-12-16 00:00:00 ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 00:00:00 ┆ 3 │
│ a ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 01:00:00 ┆ 1 │
│ a ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 03:00:00 ┆ 2021-12-16 02:00:00 ┆ 2 │
│ a ┆ 2021-12-16 03:00:00 ┆ 2021-12-16 04:00:00 ┆ 2021-12-16 03:00:00 ┆ 1 │
│ b ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 01:00:00 ┆ 2 │
│ b ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 03:00:00 ┆ 2021-12-16 02:00:00 ┆ 1 │
└────────┴─────────────────────┴─────────────────────┴─────────────────────┴───────┘
时间序列
import polars as pl
from datetime import datetime
# 创建一个数据帧实例
df = pl.DataFrame(
{
"time": pl.date_range(
low=datetime(2021, 12, 16),
high=datetime(2021, 12, 16, 3),
interval="30m",
),
"n": range(7),
}
)
df
shape: (7, 2)
┌─────────────────────┬─────┐
│ time ┆ n │
│ --- ┆ --- │
│ datetime ┆ i64 │
╞═════════════════════╪═════╡
│ 2021-12-16 00:00:00 ┆ 0 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┤
│ 2021-12-16 00:30:00 ┆ 1 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┤
│ 2021-12-16 01:00:00 ┆ 2 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┤
│ 2021-12-16 01:30:00 ┆ 3 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┤
│ 2021-12-16 02:00:00 ┆ 4 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┤
│ 2021-12-16 02:30:00 ┆ 5 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌┤
│ 2021-12-16 03:00:00 ┆ 6 │
└─────────────────────┴─────┘
从2021-12-16 00:00:00开始,按1小时的窗口分组。
(
df.groupby_dynamic("time", every="1h").agg(
[pl.col("time").min(), pl.col("time").max()]
)
)
shape: (3, 3)
┌─────────────────────┬─────────────────────┬─────────────────────┐
│ time ┆ time_min ┆ time_max │
│ --- ┆ --- ┆ --- │
│ datetime ┆ datetime ┆ datetime │
╞═════════════════════╪═════════════════════╪═════════════════════╡
│ 2021-12-16 00:00:00 ┆ 2021-12-16 00:30:00 ┆ 2021-12-16 01:00:00 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 01:00:00 ┆ 2021-12-16 01:30:00 ┆ 2021-12-16 02:00:00 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 02:00:00 ┆ 2021-12-16 02:30:00 ┆ 2021-12-16 03:00:00 │
└─────────────────────┴─────────────────────┴─────────────────────┘
窗口边界也可以添加到聚合结果中
(
df.groupby_dynamic("time", every="1h", include_boundaries=True).agg(
[pl.col("time").count()]
)
)
shape: (3, 4)
┌─────────────────────┬─────────────────────┬─────────────────────┬────────────┐
│ _lower_boundary ┆ _upper_boundary ┆ time ┆ time_count │
│ --- ┆ --- ┆ --- ┆ --- │
│ datetime ┆ datetime ┆ datetime ┆ u32 │
╞═════════════════════╪═════════════════════╪═════════════════════╪════════════╡
│ 2021-12-16 00:00:00 ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 00:00:00 ┆ 2 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 01:00:00 ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 01:00:00 ┆ 2 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 02:00:00 ┆ 2021-12-16 03:00:00 ┆ 2021-12-16 02:00:00 ┆ 2 │
└─────────────────────┴─────────────────────┴─────────────────────┴────────────┘
当closed=“left”,不应包括区间[下限、上限]的右端
(
df.groupby_dynamic("time", every="1h", closed="left").agg(
[pl.col("time").count(), pl.col("time").list()]
)
)
shape: (3, 3)
┌─────────────────────┬────────────┬─────────────────────────────────────┐
│ time ┆ time_count ┆ time_agg_list │
│ --- ┆ --- ┆ --- │
│ datetime ┆ u32 ┆ list [datetime] │
╞═════════════════════╪════════════╪═════════════════════════════════════╡
│ 2021-12-16 00:00:00 ┆ 2 ┆ [2021-12-16 00:00:00, 2021-12-16... │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 01:00:00 ┆ 2 ┆ [2021-12-16 01:00:00, 2021-12-16... │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 02:00:00 ┆ 2 ┆ [2021-12-16 02:00:00, 2021-12-16... │
└─────────────────────┴────────────┴─────────────────────────────────────┘
当closed="both",窗口边界处的时间值分为两组。
(
df.groupby_dynamic("time", every="1h", closed="both").agg(
[pl.col("time").count()]
)
)
shape: (3, 2)
┌─────────────────────┬────────────┐
│ time ┆ time_count │
│ --- ┆ --- │
│ datetime ┆ u32 │
╞═════════════════════╪════════════╡
│ 2021-12-16 00:00:00 ┆ 3 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 01:00:00 ┆ 3 │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2021-12-16 02:00:00 ┆ 3 │
└─────────────────────┴────────────┘
动态groupbys还可以与普通键上的分组相结合
pl.DataFrame(
{
"time": pl.date_range(
low=datetime(2021, 12, 16),
high=datetime(2021, 12, 16, 3),
interval="30m",
),
"groups": ["a", "a", "a", "b", "b", "a", "a"],
}
)
shape: (7, 2)
┌─────────────────────┬────────┐
│ time ┆ groups │
│ --- ┆ --- │
│ datetime ┆ str │
╞═════════════════════╪════════╡
│ 2021-12-16 00:00:00 ┆ a │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2021-12-16 00:30:00 ┆ a │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2021-12-16 01:00:00 ┆ a │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2021-12-16 01:30:00 ┆ b │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2021-12-16 02:00:00 ┆ b │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2021-12-16 02:30:00 ┆ a │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2021-12-16 03:00:00 ┆ a │
└─────────────────────┴────────┘
(
df.groupby_dynamic(
"time",
every="1h",
closed="both",
by="groups",
include_boundaries=True,
).agg([pl.col("time").count()])
)
shape: (4, 5)
┌────────┬─────────────────────┬─────────────────────┬─────────────────────┬────────────┐
│ groups ┆ _lower_boundary ┆ _upper_boundary ┆ time ┆ time_count │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ datetime ┆ datetime ┆ datetime ┆ u32 │
╞════════╪═════════════════════╪═════════════════════╪═════════════════════╪════════════╡
│ a ┆ 2021-12-16 00:00:00 ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 00:00:00 ┆ 3 │
├╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ a ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 01:00:00 ┆ 1 │
├╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ a ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 03:00:00 ┆ 2021-12-16 02:00:00 ┆ 2 │
├╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┤
│ b ┆ 2021-12-16 01:00:00 ┆ 2021-12-16 02:00:00 ┆ 2021-12-16 01:00:00 ┆ 2 │
└────────┴─────────────────────┴─────────────────────┴─────────────────────┴────────────┘
使用范围
本章包含一些片段,可以帮助您了解用Polars完成事情的惯用方法的最新信息。
IO
Polars支持不同的文件类型,其各自的解析器都是最快的。
例如,在将CSV文件交给Pandas之前,通过Polars加载CSV文件比使用Pandas加载要快。只需运行 pl.read_csv("<FILE>",rechunk=False).to_pandas()。
CSV 文件
读与写
读取CSV文件应该看起来很熟悉:
df = pl.read_csv("path.csv")
CSV文件会有非常多的样式,所以一定要去看一下
read_csv() API。
写入CSV文件可以用
write_csv()方法。
df = pl.DataFrame({"foo": [1, 2, 3], "bar": [None, "bak", "baz"]})
df.write_csv("path.csv")
扫描
Polars允许你扫描CSV文件。扫描操作延迟了对文件的实际解析,
并返回一个延迟计算的容器LazyFrame。
df = pl.scan_csv("path.csv")
如果你想了解更多这样设计的精妙之处,请移步PolarsOptimizations这一章。
Parquet 文件
加载或写入 Parquet文件快如闪电。
Pandas 使用 PyArrow(用于Apache Arrow的Python库)将Parquet数据加载到内存,但不得不将数据复制到了Pandas的内存空间中。
Polars就没有这部分额外的内存开销,因为读取Parquet时,Polars会直接复制进Arrow的内存空间,且始终使用这块内存。
读&写
df = pl.read_parquet("path.parquet")
df = pl.DataFrame({"foo": [1, 2, 3], "bar": [None, "bak", "baz"]})
df.write_parquet("path.parquet")
扫描
Polars允许你扫描Parquet输入。扫描操作延迟了对文件的实际解析,并返回一个延迟计算的容器LazyFrame。
df = pl.scan_parquet("path.parquet")
如果你想了解更多这样设计的精妙之处,请移步PolarsOptimizations这一章。
处理多个文件
Polars可以根据您的需要和内存紧张程度,以不同的方式处理多个文件。
让我们创建一些文件来使用一些上下文(context):
import polars as pl
df = pl.DataFrame({"foo": [1, 2, 3], "bar": [None, "ham", "spam"]})
for i in range(5):
df.write_csv(f"my_many_files_{i}.csv")
读入单个DataFrame
要将多个文件读入一个DataFrame,我们可以使用全局模式:
df = pl.read_csv("my_many_files_*.csv")
print(df)
shape: (15, 2)
┌─────┬──────┐
│ foo ┆ bar │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════╪══════╡
│ 1 ┆ null │
│ 2 ┆ ham │
│ 3 ┆ spam │
│ 1 ┆ null │
│ … ┆ … │
│ 3 ┆ spam │
│ 1 ┆ null │
│ 2 ┆ ham │
│ 3 ┆ spam │
└─────┴──────┘
要了解这是如何工作的,我们可以看看查询计划。下面我们可以看到,所有文件都是单独读取并连接成一个DataFrame 。Polars将尝试将读取并行化。
pl.scan_csv("my_many_files_*.csv").show_graph()

并行读取和处理
如果您的文件不必位于单个表中,您还可以为每个文件构建一个查询计划,并在Polars线程池中并行执行它们。所有查询计划的执行都是极好的并行执行,不需要任何通信。
import polars as pl
import glob
queries = []
for file in glob.glob("my_many_files_*.csv"):
q = pl.scan_csv(file).groupby("bar").agg([pl.count(), pl.sum("foo")])
queries.append(q)
dataframes = pl.collect_all(queries)
print(dataframes)
[shape: (3, 3)
┌──────┬───────┬─────┐
│ bar ┆ count ┆ foo │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ i64 │
╞══════╪═══════╪═════╡
│ spam ┆ 1 ┆ 3 │
│ null ┆ 1 ┆ 1 │
│ ham ┆ 1 ┆ 2 │
└──────┴───────┴─────┘, shape: (3, 3)
┌──────┬───────┬─────┐
│ bar ┆ count ┆ foo │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ i64 │
╞══════╪═══════╪═════╡
│ null ┆ 1 ┆ 1 │
│ ham ┆ 1 ┆ 2 │
│ spam ┆ 1 ┆ 3 │
└──────┴───────┴─────┘, shape: (3, 3)
┌──────┬───────┬─────┐
│ bar ┆ count ┆ foo │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ i64 │
╞══════╪═══════╪═════╡
│ ham ┆ 1 ┆ 2 │
│ spam ┆ 1 ┆ 3 │
│ null ┆ 1 ┆ 1 │
└──────┴───────┴─────┘, shape: (3, 3)
┌──────┬───────┬─────┐
│ bar ┆ count ┆ foo │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ i64 │
╞══════╪═══════╪═════╡
│ ham ┆ 1 ┆ 2 │
│ spam ┆ 1 ┆ 3 │
│ null ┆ 1 ┆ 1 │
└──────┴───────┴─────┘, shape: (3, 3)
┌──────┬───────┬─────┐
│ bar ┆ count ┆ foo │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ i64 │
╞══════╪═══════╪═════╡
│ ham ┆ 1 ┆ 2 │
│ null ┆ 1 ┆ 1 │
│ spam ┆ 1 ┆ 3 │
└──────┴───────┴─────┘]
读取MySQL、Postgres、Sqlite、Redshift、Clickhouse
从以上数据库中读取数据,请先安装connector-x。
$ pip install connectorx>=0.2.0a3
import polars as pl
conn = "postgres://username:password@server:port/database"
query = "SELECT * FROM foo"
pl.read_sql(query, conn)
与 AWS 交互
要读取或写入AWS存储桶,需要额外的依赖项:
$ pip install s3fs
在接下来的几个片段中,我们将演示如何与Parquet文件交互位于AWS桶上。
读入
使用如下加载一个.parquet:
import polars as pl
import pyarrow.parquet as pq
import s3fs
fs = s3fs.S3FileSystem()
bucket = "<YOUR_BUCKET>"
path = "<YOUR_PATH>"
dataset = pq.ParquetDataset(f"s3://{bucket}/{path}", filesystem=fs)
df = pl.from_arrow(dataset.read())
与 Google BigQuery 交互
读写BigQuery数据库,需要额外依赖项:
$ pip install google-cloud-bigquery
读取
从BigQuery查询并得到DataFrame,可以像这样:
import polars as pl
from google.cloud import bigquery
client = bigquery.Client()
# 执行查询
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # API 请求
rows = query_job.result() # 等待查询完成
df = pl.from_arrow(rows.to_arrow())
写入
from google.cloud import bigquery
client = bigquery.Client()
with io.BytesIO() as stream:
df.write_parquet(stream)
stream.seek(0)
job = client.load_table_from_file(
stream,
destination='tablename',
project='projectname',
job_config=bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.PARQUET,
),
)
job.result()
与 Postgres 交互
读取
从postgres数据库中读取数据,需要额外依赖项:
$ pip install connectorx>=0.2.0a3
import polars as pl
conn = "postgresql://username:password@server:port/database"
query = "SELECT * FROM foo"
pl.read_sql(query, conn)
写入
写入postgres数据库,需要额外依赖项:
$ pip install psycopg2-binary
用psycopg2写入postgres数据库,我们会用批处理的方法,限制与服务器的往返行程以提高写入性能。
我们首先要保证所有的数据类型可以被psycopg2所识别,再使用DataFrame.rows轻松将每列数据转置成数据库驱动程序可以处理的行。
from psycopg2 import sql
import psycopg2.extras
import polars as pl
# 不仿假设有一个DataFrame,其列分别为:浮点,整数,字符串,日期(date64)类型的数据
df = pl.read_parquet("somefile.parquet")
# 首先将 polars 的 date64 数据类型转换成 python 的 datetime 对象
for col in df:
# 只转换date64类型数据
if col.dtype == pl.Date64:
df = df.with_column(col.dt.to_python_datetime())
# 为字段名创建 sql 标识符
# 这一步是为了在sql语句中安全插入数据
columns = sql.SQL(",").join(sql.Identifier(name) for name in df.columns)
# 为值创建占位符,之后再被值填充
values = sql.SQL(",").join([sql.Placeholder() for _ in df.columns])
table_id = "mytable"
# 准备insert语句
insert_stmt = sql.SQL("INSERT INTO ({}) VALUES({});").format(
sql.Identifier(table_id), columns, values
)
# 创建与数据库的连接
conn = psycopg2.connect()
cur = conn.cursort()
# 执行insert语句
psycopg2.extras.execute_batch(cur, insert_stmt, df.rows())
conn.commit()
互通性
Arrow
Arrow 正在迅速地成为列式数据 事实上 的标准。这意味着对 Arrow 的支持(包括语言与工具)也在迅速增加。
由于开发者在这种格式的背后投入了大量的努力与支持,使用 Arrow 可能是完成下面任务最快的方式:
- 读写
Parquet格式的文件 - 从 CSV 读取列式数据
- 交换列式数据
Polars 使用 Arrow 内存缓冲作为 Polars Series 最基本的构建模块。
这意味着当我们要在 Polars 和 Arrow 之间交换数据时,无需对数据进行拷贝操作。
这也意味着 Polars 获得了 Arrow 带来的一切性能提升。
要将 Polars 的 DataFrame 或者 Series 转换为 Arrow,只需使用 .to_arrow() 函数。
类似的,要从 Arrow 格式导入数据,可以调用 .from_arrow() 函数。
Numpy
Polars 的 Series 支持 NumPy 的
通用函数 (ufuncs)。
调用元素层面的 (element-wise) 函数,比如 np.exp()、np.cos() 或 np.div(),基本上没有额外开销。
需要注意的是,Polars 中的缺失值是一个独立的比特掩码 —— 其在 NumPy 中是不可见的。
这可能导致窗口函数或 np.convolve() 输出有缺陷或不完整的结果。
要将一个 Polars Series 转换为 NumPy 数组,可以调用 .to_numpy() 函数。
转换时,此函数将会把缺失值替换为 np.nan。如果 Series 中没有缺失值,或转换后不再需要这些值,
可以使用 .view() 函数作为代替,这将为数据生成一个零拷贝的 NumPy 数组。
数据
字符串
由于 Arrow 后端, Polars字符串操作比使用NumPy或Pandas执行的相同操作快得多。在后者中,字符串存储为Python对象。 在遍历np.array or the pd.Series时,CPU需要跟踪所有字符串指针,并跳转到许多随机内存位置——这是非常低效的缓存。在Polars(通过Arrow数据结构)中,字符串在内存中是连续的。因此,对于CPU来说,遍历缓存是最优的,也是可预测的。
Polars中可用的字符串处理函数可以在 ``str` namespace 中找到。
下面是几个例子。要计算字符串长度,请执行以下操作:
import polars as pl
df = pl.DataFrame({"shakespeare": "All that glitters is not gold".split(" ")})
df = df.with_columns(pl.col("shakespeare").str.lengths().alias("letter_count"))
返回:
shape: (6, 2)
┌─────────────┬──────────────┐
│ shakespeare ┆ letter_count │
│ --- ┆ --- │
│ str ┆ u32 │
╞═════════════╪══════════════╡
│ All ┆ 3 │
│ that ┆ 4 │
│ glitters ┆ 8 │
│ is ┆ 2 │
│ not ┆ 3 │
│ gold ┆ 4 │
└─────────────┴──────────────┘
下面是从句子中过滤出冠词(the、a、and、etc.)的正则表达式模式:
import polars as pl
df = pl.DataFrame({"a": "The man that ate a whole cake".split(" ")})
df = df.filter(pl.col("a").str.contains(r"(?i)^the$|^a$").is_not())
输出:
shape: (5, 1)
┌───────┐
│ a │
│ --- │
│ str │
╞═══════╡
│ man │
│ that │
│ ate │
│ whole │
│ cake │
└───────┘
时间戳
Polars 提供了4时间数据类型:
pl.Date, 用于日期对象:自UNIX纪元以来的天数,为32位有符号整数。pl.Datetime, 用于datetime项目:自UNIX纪元以来的纳秒数,为64位有符号整数。pl.Time, 编码为午夜后的纳秒数。
Polars 字符串(pl.Utf8) 数据类型可以解析为它们中的任何一个。您可以让Polars尝试猜测日期[time]的格式,或者显式提供fmt规则。
举例来说(查看此此链接以获取全面列表):
"%Y-%m-%d"对于"2020-12-31""%Y/%B/%d"对于"2020/December/31""%B %y"对于"December 20"
下面是一个简单的例子:
import polars as pl
dataset = pl.DataFrame({"date": ["2020-01-02", "2020-01-03", "2020-01-04"], "index": [1, 2, 3]})
q = dataset.lazy().with_columns(pl.col("date").str.strptime(pl.Date, "%Y-%m-%d"))
df = q.collect()
返回:
shape: (3, 2)
┌────────────┬───────┐
│ date ┆ index │
│ --- ┆ --- │
│ date ┆ i64 │
╞════════════╪═══════╡
│ 2020-01-02 ┆ 1 │
│ 2020-01-03 ┆ 2 │
│ 2020-01-04 ┆ 3 │
└────────────┴───────┘
所有datetime功能都显示在 dt 命名空间中。
数据帧
选中行或列
对行或列进行选择的操作与其他数据框架库类似。
选中列
# 推荐写法
df.select(["a", "b"])
# 也可以写成这样
df(["a", "b"])
shape: (5, 2)
┌──────┬──────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ str │
╞══════╪══════╡
│ 1 ┆ foo │
│ 2 ┆ ham │
│ 3 ┆ spam │
│ null ┆ egg │
│ 5 ┆ null │
└──────┴──────┘
选中行
df[0:2]
shape: (2, 4)
┌─────┬─────┬──────────┬─────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞═════╪═════╪══════════╪═════╡
│ 1 ┆ foo ┆ 0.37454 ┆ a │
│ 2 ┆ ham ┆ 0.950714 ┆ b │
└─────┴─────┴──────────┴─────┘
常用操作
与许多其他数据框架库一样,Polars 提供了大量的常用函数来对 Dataframe 进行操作。
熟悉 Dataframes 的用户会发现 Polars 与 Pandas 或 R 的实现有许多相似之处。
添加列
out = df.with_columns(pl.Series(["p", "q", "r", "s", "t"]).alias("e")) # .alias方法增加一列
print(out)
shape: (5, 5)
┌──────┬──────┬──────────┬─────┬─────┐
│ a ┆ b ┆ c ┆ d ┆ e │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str ┆ str │
╞══════╪══════╪══════════╪═════╪═════╡
│ 1 ┆ foo ┆ 0.37454 ┆ a ┆ p │
│ 2 ┆ ham ┆ 0.950714 ┆ b ┆ q │
│ 3 ┆ spam ┆ 0.731994 ┆ c ┆ r │
│ null ┆ egg ┆ 0.598658 ┆ d ┆ s │
│ 5 ┆ null ┆ 0.156019 ┆ e ┆ t │
└──────┴──────┴──────────┴─────┴─────┘
类型转换
这个例子使用的是 Python 数据类型,但我们也可以在 Polars dtypes
(如 pl.Float32、pl.Float64)之间进行转换。
out = df.with_columns(pl.col("a").cast(float))
print(out)
shape: (5, 4)
┌──────┬──────┬──────────┬─────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ f64 ┆ str ┆ f64 ┆ str │
╞══════╪══════╪══════════╪═════╡
│ 1.0 ┆ foo ┆ 0.37454 ┆ a │
│ 2.0 ┆ ham ┆ 0.950714 ┆ b │
│ 3.0 ┆ spam ┆ 0.731994 ┆ c │
│ null ┆ egg ┆ 0.598658 ┆ d │
│ 5.0 ┆ null ┆ 0.156019 ┆ e │
└──────┴──────┴──────────┴─────┘
重命名列
import numpy as np
import polars as pl
df = pl.DataFrame(
{
"a": [1, 2, 3, None, 5],
"b": ["foo", "ham", "spam", "egg", None],
"c": np.random.rand(5),
"d": ["a", "b", "c", "d", "e"],
}
)
df.columns = ["banana", "orange", "apple", "grapefruit"] # 重命名列
shape: (5, 4)
┌────────┬────────┬──────────┬────────────┐
│ banana ┆ orange ┆ apple ┆ grapefruit │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞════════╪════════╪══════════╪════════════╡
│ 1 ┆ foo ┆ 0.155995 ┆ a │
│ 2 ┆ ham ┆ 0.058084 ┆ b │
│ 3 ┆ spam ┆ 0.866176 ┆ c │
│ null ┆ egg ┆ 0.601115 ┆ d │
│ 5 ┆ null ┆ 0.708073 ┆ e │
└────────┴────────┴──────────┴────────────┘
删除列
# 删除单独的列
out = df.drop("d")
# 删除多个列
out = df.drop(["b", "c"])
# 选择所有列但是不包括('b', 'c')
out = df.select(pl.all().exclude(["b", "c"]))
# 仅选择列"a"
out = df.select(pl.col("a"))
shape: (5, 1)
┌──────┐
│ a │
│ --- │
│ i64 │
╞══════╡
│ 1 │
│ 2 │
│ 3 │
│ null │
│ 5 │
└──────┘
删除空值
df.drop_nulls()
shape: (3, 4)
┌─────┬──────┬──────────┬─────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞═════╪══════╪══════════╪═════╡
│ 1 ┆ foo ┆ 0.37454 ┆ a │
│ 2 ┆ ham ┆ 0.950714 ┆ b │
│ 3 ┆ spam ┆ 0.731994 ┆ c │
└─────┴──────┴──────────┴─────┘
填充缺失值(NA)
策略:
mean:平均值backward:上一值min:最小值max:最大值
df.fill_none("forward")
shape: (5, 4)
┌─────┬──────┬──────────┬─────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞═════╪══════╪══════════╪═════╡
│ 1 ┆ foo ┆ 0.37454 ┆ a │
│ 2 ┆ ham ┆ 0.950714 ┆ b │
│ 3 ┆ spam ┆ 0.731994 ┆ c │
│ 3 ┆ egg ┆ 0.598658 ┆ d │
│ 5 ┆ egg ┆ 0.156019 ┆ e │
└─────┴──────┴──────────┴─────┘
获取所有列
df.columns
['a', 'b', 'c', 'd']
空值计数
df.null_count()
shape: (1, 4)
┌─────┬─────┬─────┬─────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ u32 ┆ u32 ┆ u32 ┆ u32 │
╞═════╪═════╪═════╪═════╡
│ 1 ┆ 1 ┆ 0 ┆ 0 │
└─────┴─────┴─────┴─────┘
列排序
df.sort("a", reverse=True)
shape: (5, 4)
┌──────┬──────┬──────────┬─────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞══════╪══════╪══════════╪═════╡
│ null ┆ egg ┆ 0.598658 ┆ d │
│ 5 ┆ null ┆ 0.156019 ┆ e │
│ 3 ┆ spam ┆ 0.731994 ┆ c │
│ 2 ┆ ham ┆ 0.950714 ┆ b │
│ 1 ┆ foo ┆ 0.37454 ┆ a │
└──────┴──────┴──────────┴─────┘
转为 NumPy
df.to_numpy()
[[1.0 'foo' 0.3745401188473625 'a']
[2.0 'ham' 0.9507143064099162 'b']
[3.0 'spam' 0.7319939418114051 'c']
[nan 'egg' 0.5986584841970366 'd']
[5.0 None 0.15601864044243652 'e']]
转为 Pandas
df.to_pandas()
a b c d
0 1.0 foo 0.374540 a
1 2.0 ham 0.950714 b
2 3.0 spam 0.731994 c
3 NaN egg 0.598658 d
4 5.0 None 0.156019 e
分组
急性 & 惰性
分组操作的语法在两个 API 中是类似的 —— 二者中均可使用表达式。
要完成分组操作,先调用 .groupby() 函数,并跟随一个 .agg() 函数。
在 .agg() 函数中,你可以对任意数量的列进行任意聚合操作。
要对所有列进行聚合,可以使用通配符表达式:
.agg(pl.col("*").sum())。
来看一个简单的(惰性)例子:
import polars as pl
q = (
pl.scan_csv("data/reddit.csv")
.groupby("comment_karma")
.agg([pl.col("name").n_unique().alias("unique_names"), pl.max("link_karma")])
.sort(by="unique_names", descending=True) # 逆序排列,reverse=True
)
df = q.fetch()
这将返回下面的结果:
shape: (100, 3)
┌───────────────┬──────────────┬────────────┐
│ comment_karma ┆ unique_names ┆ link_karma │
│ --- ┆ --- ┆ --- │
│ i64 ┆ u32 ┆ i64 │
╞═══════════════╪══════════════╪════════════╡
│ 0 ┆ 367 ┆ 611 │
│ 1 ┆ 9 ┆ 22 │
│ 3 ┆ 6 ┆ 1 │
│ 38 ┆ 4 ┆ 291 │
│ … ┆ … ┆ … │
│ -5 ┆ 1 ┆ 0 │
│ 232 ┆ 1 ┆ 47 │
│ 835 ┆ 1 ┆ 1154 │
│ 431 ┆ 1 ┆ 8 │
└───────────────┴──────────────┴────────────┘
聚合
你可以调用 .select() 函数或使用 .with_column()/.with_columns() 上下文进行列聚合操作。
要对所有列进行聚合,可以使用通配符表达式:
.select(pl.col("*").sum())。
以下面的代码为例:
import polars as pl
# 扫描级导入csv数据集
q = pl.scan_csv("data/reddit.csv").select([pl.sum("comment_karma"), pl.min("link_karma")])
df = q.fetch()
其结果为:
shape: (1, 2)
┌───────────────┬────────────┐
│ comment_karma ┆ link_karma │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═══════════════╪════════════╡
│ 242649 ┆ -109 │
└───────────────┴────────────┘
更多内容请参见表达式 的 API 文档。
过滤
急性
Polars 的急性过滤操作与 Pandas 中的非常相似。
import polars as pl
df = pl.DataFrame({"a": [1, 2, 3], "b": [None, "b", "c"]})
mask = df["a"] > 2 # 谓词表达式
out = df[mask] # 谓词过滤
或者用下面更符合 Polars 习惯的方式:
df.filter(pl.col("a") > 2)
惰性
惰性过滤操作通常使用以下表达:
df = pl.DataFrame({"a": [1, 2, 3], "b": [None, "b", "c"]})
out = df.lazy().filter(pl.col("a") > 2).collect() # 惰性过滤
两者的结果都是:
shape: (1, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════╪═════╡
│ 3 ┆ c │
└─────┴─────┘
连接
类似于其他数据框架库,Polars 支持一系列连接操作。
- 在单个或多个列上进行连接
- 左连接
- 内连接
- 外连接
数据集
import polars as pl
df_a = pl.DataFrame({"a": [1, 2, 1, 1], "b": ["a", "b", "c", "c"], "c": [0, 1, 2, 3]})
df_b = pl.DataFrame({"foo": [1, 1, 1], "bar": ["a", "c", "c"], "ham": ["let", "var", "const"]})
print(df_a)
shape: (4, 3)
┌─────┬─────┬─────┐
│ a ┆ b ┆ c │
│ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 │
╞═════╪═════╪═════╡
│ 1 ┆ a ┆ 0 │
│ 2 ┆ b ┆ 1 │
│ 1 ┆ c ┆ 2 │
│ 1 ┆ c ┆ 3 │
└─────┴─────┴─────┘
print(df_b)
shape: (3, 3)
┌─────┬─────┬───────┐
│ foo ┆ bar ┆ ham │
│ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str │
╞═════╪═════╪═══════╡
│ 1 ┆ a ┆ let │
│ 1 ┆ c ┆ var │
│ 1 ┆ c ┆ const │
└─────┴─────┴───────┘
急性
out = df_a.join(df_b, left_on=["a", "b"], right_on=["foo", "bar"], how="left")
print(out)
shape: (6, 4)
┌─────┬─────┬─────┬───────┐
│ a ┆ b ┆ c ┆ ham │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ str │
╞═════╪═════╪═════╪═══════╡
│ 1 ┆ a ┆ 0 ┆ let │
│ 2 ┆ b ┆ 1 ┆ null │
│ 1 ┆ c ┆ 2 ┆ var │
│ 1 ┆ c ┆ 2 ┆ const │
│ 1 ┆ c ┆ 3 ┆ var │
│ 1 ┆ c ┆ 3 ┆ const │
└─────┴─────┴─────┴───────┘
惰性
q = df_a.lazy().join(df_b.lazy(), left_on="a", right_on="foo", how="outer")
out = q.collect()
print(out)
shape: (10, 5)
┌─────┬─────┬─────┬──────┬───────┐
│ a ┆ b ┆ c ┆ bar ┆ ham │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ str ┆ str │
╞═════╪═════╪═════╪══════╪═══════╡
│ 1 ┆ a ┆ 0 ┆ a ┆ let │
│ 1 ┆ a ┆ 0 ┆ c ┆ var │
│ 1 ┆ a ┆ 0 ┆ c ┆ const │
│ 2 ┆ b ┆ 1 ┆ null ┆ null │
│ … ┆ … ┆ … ┆ … ┆ … │
│ 1 ┆ c ┆ 2 ┆ c ┆ const │
│ 1 ┆ c ┆ 3 ┆ a ┆ let │
│ 1 ┆ c ┆ 3 ┆ c ┆ var │
│ 1 ┆ c ┆ 3 ┆ c ┆ const │
└─────┴─────┴─────┴──────┴───────┘
重塑
重塑操作将一个宽格式的 DataFrame 逆透视为长格式。
数据集
import polars as pl
df = pl.DataFrame({"A": ["a", "b", "a"], "B": [1, 3, 5], "C": [10, 11, 12], "D": [2, 4, 6]})
print(df)
shape: (3, 4)
┌─────┬─────┬─────┬─────┐
│ A ┆ B ┆ C ┆ D │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ i64 ┆ i64 │
╞═════╪═════╪═════╪═════╡
│ a ┆ 1 ┆ 10 ┆ 2 │
│ b ┆ 3 ┆ 11 ┆ 4 │
│ a ┆ 5 ┆ 12 ┆ 6 │
└─────┴─────┴─────┴─────┘
急性 + 惰性
急性 与 惰性 操作的 API 相同。
out = df.melt(id_vars=["A", "B"], value_vars=["C", "D"])
print(out)
shape: (6, 4)
┌─────┬─────┬──────────┬───────┐
│ A ┆ B ┆ variable ┆ value │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ str ┆ i64 │
╞═════╪═════╪══════════╪═══════╡
│ a ┆ 1 ┆ C ┆ 10 │
│ b ┆ 3 ┆ C ┆ 11 │
│ a ┆ 5 ┆ C ┆ 12 │
│ a ┆ 1 ┆ D ┆ 2 │
│ b ┆ 3 ┆ D ┆ 4 │
│ a ┆ 5 ┆ D ┆ 6 │
└─────┴─────┴──────────┴───────┘
透视
在 DataFrame 中透视一列,并执行下列其中一种聚合。
- first:第一项
- sum:求和
- min:最小值
- max:最大值
- mean:平均值
- median:中位数
透视操作包括一个或多个列的分组(它们将成为新的 y 轴),将被透视的列(它们将成为新的 x 轴)以及一个聚合。
数据集
import polars as pl
# 构造DataFrame(数据帧)
df = pl.DataFrame(
{
"foo": ["A", "A", "B", "B", "C"],
"N": [1, 2, 2, 4, 2],
"bar": ["k", "l", "m", "n", "o"],
}
)
print(df)
shape: (5, 3)
┌─────┬─────┬─────┐
│ foo ┆ N ┆ bar │
│ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ str │
╞═════╪═════╪═════╡
│ A ┆ 1 ┆ k │
│ A ┆ 2 ┆ l │
│ B ┆ 2 ┆ m │
│ B ┆ 4 ┆ n │
│ C ┆ 2 ┆ o │
└─────┴─────┴─────┘
急性
out = df.pivot(
index="foo",
columns="bar",
values="N",
)
惰性
惰性操作的 API 中并不包含转置操作,因此想要惰性地使用转置,我们可以使用 map 来
在惰性计算节点中执行一个急性的自定义函数。
q = (
df.lazy()
.collect()
.pivot(
index="foo",
columns="bar",
values="N",
)
.lazy()
)
out = q.collect()
print(out)
shape: (3, 6)
┌─────┬──────┬──────┬──────┬──────┬──────┐
│ foo ┆ k ┆ l ┆ m ┆ n ┆ o │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═════╪══════╪══════╪══════╪══════╪══════╡
│ A ┆ 1 ┆ 2 ┆ null ┆ null ┆ null │
│ B ┆ null ┆ null ┆ 2 ┆ 4 ┆ null │
│ C ┆ null ┆ null ┆ null ┆ null ┆ 2 │
└─────┴──────┴──────┴──────┴──────┴──────┘
排序
Polars 支持与其他数据框架库类似的排序行为,即按一个或多个列以及多个(不同的)顺序进行排序。
数据集
import numpy as np
import polars as pl
df = pl.DataFrame({"a": np.arange(1, 4), "b": ["a", "a", "b"]}) # np.arange(1, 4): 生成[1, 4)的数组
print(df)
shape: (3, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════╪═════╡
│ 1 ┆ a │
│ 2 ┆ a │
│ 3 ┆ b │
└─────┴─────┘
急性
out = df.sort(["b", "a"], descending=[True, False]) # 分别对两列"b", "a"进行排序,"b"逆序,"a"顺序
print(out)
shape: (3, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════╪═════╡
│ 1 ┆ a │
│ 2 ┆ a │
│ 3 ┆ b │
└─────┴─────┘
惰性
import polars as pl
q = df.lazy().sort(pl.col("a"), descending=True) # 惰性排序,对"a"列
df = q.collect()
print(out)
shape: (3, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════╪═════╡
│ 3 ┆ b │
│ 2 ┆ a │
│ 1 ┆ a │
└─────┴─────┘
条件应用
要修改一个 Series 或 DataFrame 中的一列,需要以下两步。
- 基于一些谓词创建一个
boolean掩码 - 替换掉掩码评估为
True的值 - (仅当惰性操作时) 定义掩码评估为
False的值
数据集
import numpy as np
import polars as pl
# 构造数据帧
df = pl.DataFrame({"range": np.arange(10), "left": ["foo"] * 10, "right": ["bar"] * 10})
df.head()
shape: (5, 3)
┌───────┬──────┬───────┐
│ range ┆ left ┆ right │
│ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str │
╞═══════╪══════╪═══════╡
│ 0 ┆ foo ┆ bar │
│ 1 ┆ foo ┆ bar │
│ 2 ┆ foo ┆ bar │
│ 3 ┆ foo ┆ bar │
│ 4 ┆ foo ┆ bar │
└───────┴──────┴───────┘
我们可以使用 .when()/.then()/.otherwise() 表达式。
when- 接受一个谓词表达式then- 当谓词 == True时使用的表达式otherwise- 当谓词 == False时使用的表达式
请参见以下例子。
q = df.lazy().with_columns(
pl.when(pl.col("range") >= 5).then(pl.col("left")).otherwise(pl.col("right")).alias("foo_or_bar") # .alias增加一列
)
df = q.collect()
print(df)
shape: (10, 4)
┌───────┬──────┬───────┬────────────┐
│ range ┆ left ┆ right ┆ foo_or_bar │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str │
╞═══════╪══════╪═══════╪════════════╡
│ 0 ┆ foo ┆ bar ┆ bar │
│ 1 ┆ foo ┆ bar ┆ bar │
│ 2 ┆ foo ┆ bar ┆ bar │
│ 3 ┆ foo ┆ bar ┆ bar │
│ … ┆ … ┆ … ┆ … │
│ 6 ┆ foo ┆ bar ┆ foo │
│ 7 ┆ foo ┆ bar ┆ foo │
│ 8 ┆ foo ┆ bar ┆ foo │
│ 9 ┆ foo ┆ bar ┆ foo │
└───────┴──────┴───────┴────────────┘
应用
自定义函数
总会有一个操作非常特殊,以至于人们无法用Polars的公共方法来完成它。幸运的是,polars允许您应用自定义函数。这意味着可以定义一个Python函数(或lambda),并将其传递给逻辑计划。
假设我们想要以一种迫切(eager)的方式将一个映射操作应用于一个Polars Series。这可以按如下所示进行:
import polars as pl
my_map = {1: "foo", 2: "bar", 3: "ham", 4: "spam", 5: "eggs"}
s = pl.Series("a", [1, 2, 3, 4, 5]) # 构建Series
s = s.apply(lambda x: my_map[x]) # 用lambda表达式添加Series
返回:
shape: (5,)
Series: 'a' [str]
[
"foo"
"bar"
"ham"
"spam"
"eggs"
]
然而,由于Polars Series只能包含一个数据类型,因此存在一些问题。
在上面的apply()方法中我们没有指定Series应该包含的数据类型Polars试图通过调用提供的函数本身来提前推断输出数据类型。如果它后来得到的数据类型与最初推断的类型不匹配,则该值将被指示为缺失(null)。
如果输出数据类型已知,建议将该信息提供给Polars(通过.apply()的dtype选项)。
注意,应用函数后可能会更改数据类型:我们上面使用的lambda得到一个整数作为输入,并在my_map字典中找到正确的键后返回一个字符串(pl.Utf8)。
使用map或者apply?
使用自定义函数有两种方法,一种是使用map,另一种是使用apply。您需要哪一个取决于使用自定义函数的上下文:
-
apply- 选择上下文:自定义函数应用于所有值
Fn(value) -> y - 聚合上下文:自定义函数应用于所有组
Fn([group_value_1, ... group_value_n]) -> y
- 选择上下文:自定义函数应用于所有值
-
map- 选择上下文:自定义函数应用于
Series,并且必须生成一个新的SeriesFn(Series) -> Series - 聚合上下文:自定义函数应用于
Series,并且必须生成一个新的SeriesFn(Series) -> Series
- 选择上下文:自定义函数应用于
窗口函数
Polars 支持窗口函数,灵感来自于PostgreSQL. Pandas 用户可能会将其识别为a groupby.transform(aggregation).
Polars 窗口函数比Pandas转换(transform)函数更加优雅. 我们可以在一个表达式中的多个列上应用多个函数!
import polars as pl
dataset = pl.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
}
)
q = dataset.lazy().with_columns(
[
pl.sum("A").over("fruits").alias("fruit_sum_A"), # 在"fruits"列的基础上进行"A"的加和,并另起一列
pl.first("B").over("fruits").alias("fruit_first_B"),
pl.max("B").over("cars").alias("cars_max_B"),
]
)
df = q.collect()
shape: (5, 7)
┌─────┬────────┬─────┬────────┬─────────────┬───────────────┬────────────┐
│ A ┆ fruits ┆ B ┆ cars ┆ fruit_sum_A ┆ fruit_first_B ┆ cars_max_B │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ str ┆ i64 ┆ i64 ┆ i64 │
╞═════╪════════╪═════╪════════╪═════════════╪═══════════════╪════════════╡
│ 1 ┆ banana ┆ 5 ┆ beetle ┆ 8 ┆ 5 ┆ 5 │
│ 2 ┆ banana ┆ 4 ┆ audi ┆ 8 ┆ 5 ┆ 4 │
│ 3 ┆ apple ┆ 3 ┆ beetle ┆ 7 ┆ 3 ┆ 5 │
│ 4 ┆ apple ┆ 2 ┆ beetle ┆ 7 ┆ 3 ┆ 5 │
│ 5 ┆ banana ┆ 1 ┆ beetle ┆ 8 ┆ 5 ┆ 5 │
└─────┴────────┴─────┴────────┴─────────────┴───────────────┴────────────┘
性能
本章介绍了一些Polars实现最大性能所需的技巧。
如果使用得当,Polars可以以极快的速度运行。请在H2O AI database benchmark中看结果。
字符串
了解Arrow和Polars使用的内存格式可以真正提高查询的性能. 对于大型字符串数据尤其如此。下图显示了Arrow UTF8数组在内存中的布局。
数组[“foo”、“bar”、“ham”]由以下编码:
- 连接字符串
foobarham, - 一个偏移数组,指示每个字符串
[0,2,5,8]的开始(和结束), - 空位图,指示空值。
![]()
如果我们要读取字符串值,这种内存结构的缓存效率非常高。
尤其是如果我们将它与Vec<String>(在Rust中由堆分配的字符串数据组成的数组)进行比较。

然而,如果我们需要对Arrow UTF8数组重新排序,我们需要交换字符串值的所有字节,这在处理大型字符串时可能会非常昂贵。另一方面,对于Vec<String>,我们只需要交换指针,只需移动8字节的数据,成本很低。
由于一项操作(过滤、连接、分组等)而嵌入大量Utf8 Series的DataFrame的重新排序可能很快变得非常昂贵。
范畴型
因此,Polars有一个CategoricalType。category Series是一个数组,其中填充了u32值,每个值代表一个唯一的字符串值。因此,在保持缓存效率的同时,移动值的成本也很低。
在下面的示例中,我们将演示如何将一个Utf8 Series列强制转换为一个Categorical Series。
import polars as pl
df["utf8-column"].cast(pl.Categorical)
在分类数据上加入多个数据帧
当需要基于字符串数据连接两个DataFrame时,需要同步Category数据(df1的A列中的数据需要指向与df2中的B列相同的底层字符串数据)。可以通过在StringCache上下文管理器中强制转换数据来实现。这将在该上下文管理器期间同步所有可发现的字符串值。如果希望全局字符串缓存在整个运行期间存在,可以将toggle_string_cache设置为True。
import polars as pl
df1 = pl.DataFrame({"a": ["foo", "bar", "ham"], "b": [1, 2, 3]})
df2 = pl.DataFrame({"a": ["foo", "spam", "eggs"], "c": [3, 2, 2]})
with pl.StringCache():
df1.with_columns(pl.col("a").cast(pl.Categorical))
df2.with_columns(pl.col("a").cast(pl.Categorical))
惰性连接分类数据上的多个数据帧
在查询期间(直到调用.collect()),惰性查询始终具有全局字符串缓存(除非您选择退出)。下面的示例显示了如何将两个DataFrame与Category类型连接起来。
import polars as pl
lf1 = pl.DataFrame({"a": ["foo", "bar", "ham"], "b": [1, 2, 3]}).lazy()
lf2 = pl.DataFrame({"a": ["foo", "spam", "eggs"], "c": [3, 2, 2]}).lazy()
lf1 = lf1.with_columns(pl.col("a").cast(pl.Categorical))
lf2 = lf2.with_columns(pl.col("a").cast(pl.Categorical))
lf1.join(lf2, on="a", how="inner")
优化
本章将研究Polars应用的一些查询优化器,通过查看一些示例来了解Polars如何修改原始查询计划。
惰性方法
为了展示惰性Polars功能,我们将探索两种中大型用户名数据集:
Reddit用户名数据集 包含6900多万行
import polars as pl
from ..paths import DATA_DIR
dataset = pl.read_csv(f"{DATA_DIR}/reddit.csv", n_rows=10)
shape: (5, 6)
┌─────┬──────────────────────────┬─────────────┬────────────┬───────────────┬────────────┐
│ id ┆ name ┆ created_utc ┆ updated_on ┆ comment_karma ┆ link_karma │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═════╪══════════════════════════╪═════════════╪════════════╪═══════════════╪════════════╡
│ 1 ┆ truman48lamb_jasonbroken ┆ 1397113470 ┆ 1536527864 ┆ 0 ┆ 0 │
│ 2 ┆ johnethen06_jasonbroken ┆ 1397113483 ┆ 1536527864 ┆ 0 ┆ 0 │
│ 3 ┆ yaseinrez_jasonbroken ┆ 1397113483 ┆ 1536527864 ┆ 0 ┆ 1 │
│ 4 ┆ Valve92_jasonbroken ┆ 1397113503 ┆ 1536527864 ┆ 0 ┆ 0 │
│ 5 ┆ srbhuyan_jasonbroken ┆ 1397113506 ┆ 1536527864 ┆ 0 ┆ 0 │
└─────┴──────────────────────────┴─────────────┴────────────┴───────────────┴────────────┘
以及Runescape用户名数据集 包含约5500多万条记录。
import polars as pl
from ..paths import DATA_DIR
dataset = pl.read_csv(f"{DATA_DIR}/runescape.csv", has_header=False, n_rows=10)
shape: (5, 1)
┌─────────────┐
│ column_1 │
│ --- │
│ str │
╞═════════════╡
│ a000 │
│ a0000 │
│ a000000 │
│ a0000000 │
│ a0000000000 │
└─────────────┘
谓词下推
谓词下推是Polars所做的优化,可以减少查询时间和内存使用。谓词是数据库行话,用于在某个表上应用过滤器,从而减少该表上的行数。
那么,让我们看看是否可以加载一些Reddit数据并对几个谓词进行过滤。
import polars as pl
from ..paths import DATA_DIR
q1 = (
pl.scan_csv(f"{DATA_DIR}/reddit.csv")
.filter(pl.col("comment_karma") > 0) # 谓词过滤
.filter(pl.col("link_karma") > 0)
.filter(pl.col("name").str.contains(r"^a")) # filter name that start with an "a"
)
如果我们在上面运行这个查询,什么都不会发生!这是由于懒惰的评估。 除非特别要求,否则不会发生任何事情。这使Polars能够看到查询的整个上下文,并及时优化以执行。
.collect方法请求执行。这将查询所有可用数据。
在编写、优化和检查查询时,这通常是不可取的。另一个调用执行的方法是.fetch方法。.fetch接受一个参数n_rows,并尝试在数据源上'获取'该数量的行(尽管没有给出任何保证)。
因此,让我们从源文件中“获取”约1000万行,并应用谓词。
q1.fetch(n_rows=int(1e7))
shape: (656, 6)
┌─────────┬─────────────┬─────────────┬────────────┬───────────────┬────────────┐
│ id ┆ name ┆ created_utc ┆ updated_on ┆ comment_karma ┆ link_karma │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═════════╪═════════════╪═════════════╪════════════╪═══════════════╪════════════╡
│ 77860 ┆ aquarin ┆ 1137474000 ┆ 1536528294 ┆ 150 ┆ 11 │
│ 77974 ┆ aadvaark ┆ 1137301200 ┆ 1536528294 ┆ 26 ┆ 47 │
│ 78004 ┆ apoisel ┆ 1137301200 ┆ 1536497404 ┆ 42 ┆ 2549 │
│ 78041 ┆ aonic ┆ 1137301200 ┆ 1536497404 ┆ 2931 ┆ 2095 │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 1192656 ┆ atothedrian ┆ 1162785880 ┆ 1536497412 ┆ 748 ┆ 585 │
│ 1204607 ┆ akbusiness ┆ 1162899425 ┆ 1536532995 ┆ 73 ┆ 512 │
│ 1214809 ┆ aaminics ┆ 1162969322 ┆ 1536533034 ┆ 22 ┆ 6 │
│ 1225341 ┆ antonulrich ┆ 1163110623 ┆ 1536497412 ┆ 9304 ┆ 1782 │
└─────────┴─────────────┴─────────────┴────────────┴───────────────┴────────────┘
上面我们看到,从1000万行中,61503行匹配我们的谓词。
分解
在Polars中,我们可以可视化查询计划。我们来看看。
q1.show_graph(optimized=False)
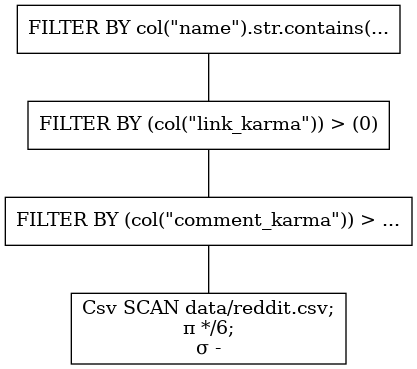
精明的读者可能会注意到,我们的查询不是很理想,因为我们有三个独立的FILTER节点。这意味着在每一个过滤器分配一个新的DataFrame,它将被输入到下一个过滤器中,然后从内存中删除--这一定是多余的,你知道吗... 他们是对的。谓词应该组合在一起。我们应该写下这个问题:
import polars as pl
from ..paths import DATA_DIR
q2 = pl.scan_csv(f"{DATA_DIR}/reddit.csv").filter(
(pl.col("comment_karma") > 0) & (pl.col("link_karma") > 0) & (pl.col("name").str.contains(r"^a"))
)
这将转化为:
q2.show_graph(optimized=False)
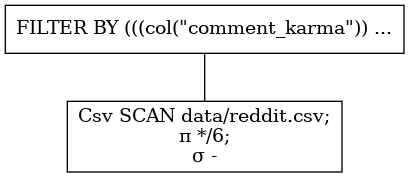
正如我们所见,谓词是组合在一起的。这将减少数据的复制。
优化随之而来
Polars试图从查询编写器中节省这种精神开销,并为您组合谓词。除此之外,它还将谓词下推到扫描级别!让我们看看优化后的查询是什么样子。
q1.show_graph(optimized=True)

这可能很难看到,但很清楚的是,只有一个节点:CSV扫描。谓词过滤是在读取csv的过程中完成的。这意味着该查询的内存开销通过过滤因子减少了!这产生了巨大的影响。
内存
正如我们所看到的,在过滤器之后还剩下约62000行。这意味着(除了批量大小和筛选操作的一些内存开销)我们使用\(\frac{6.2\text{e-}4}{1\text{e-}7} \sim 0.6 \text{%} \)在一次急切的评估中,我们将首先读取内存中的整个表,然后再应用过滤器。
性能
在撰写本文时,谓词下推也提高了查询时间性能。
无优化, predicate_pushdown=False 标签:
real 0m2,401s
user 0m5,457s
sys 0m0,894s
有优化, predicate_pushdown=True 标签:
real 0m1,597s
user 0m6,143s
sys 0m0,647s
关系代数
在查询计划的可视化中,您会看到一个\(\sigma\)符号。这表示在扫描级别执行的谓词。还有一个\(\pi\)符号表示投影(用于列选择的数据库行话),但我们稍后将讨论这个问题。
更便捷的联结(joins)操作
谓词下推优化通常也会导致更便宜的连接。连接是一个昂贵的操作。连接操作中的行数越少,成本就越低。
投影下推
我们来把上一章节中的查询与在 Runescape (一款游戏)数据中进行 FILTER 操作的结果结合起来,
来找出以字母 a 开头且玩过 Runescape 的流行 Reddit 用户名。相信你一定也会对此感兴趣的!
你可以构建类似于以下的查询:
import polars as pl
from ..paths import DATA_DIR
reddit = (
pl.scan_csv(f"{DATA_DIR}/reddit.csv")
.filter(pl.col("comment_karma") > 0)
.filter(pl.col("link_karma") > 0)
.filter(pl.col("name").str.contains(r"^a"))
)
runescape = pl.scan_csv("data/runescape.csv", has_header=False).select(pl.col("column_1").alias("name"))
dataset = reddit.join(runescape, on="name", how="inner").select(["name", "comment_karma", "link_karma"])
df1 = dataset.fetch(int(1e7))
df2 = dataset.fetch(int(1e7), predicate_pushdown=True, projection_pushdown=True)
这将产出以下 DataFrame:
shape: (0, 3)
┌──────┬───────────────┬────────────┐
│ name ┆ comment_karma ┆ link_karma │
│ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ i64 │
╞══════╪═══════════════╪════════════╡
└──────┴───────────────┴────────────┘
更近一步
让我们再来看看查询计划。
dataset.show_graph(optimized=False)

现在,我们关注的是用 π 表示的投影。第一个节点上显示着 π 3/6,这意味着我们从 DataFrame
的 6 列中选出了其中的 3 列。在 csv 读取结果中,我们可以看到通配符 π */6 和 π */1,
这意味着我们选中了 Reddit 数据集中的全部 6 列,以及对应的 Runescape 数据集中唯一的一列。
但是,这样的查询性能并不理想 —— 我们选中了两个数据集的所有列,却只显示了关联 (join) 后的 3 列。
这意味着一些参与关联计算的列实际上是可以被忽略的。类似的,在读取 csv 时解析了一些列,而它们在最后是被白白丢弃掉的。
当我们要处理的 DataFrame 中有大量的列时,所做的这种冗余工作量可能是非常可观的。
更优查询方案
让我们看看 Polars 是如何优化这个查询的。
dataset.show_graph(optimized=True)

关联 (join) 操作中的投影被下推至 csv 读取的这一步。这意味着查询优化降低了读取数据以及关联操作这二者的开销。
性能
让我们为优化前后的结果进行计时。
优化前,即 predicate_pushdown=False 且 projection_pushdown=False。
real 0m3,273s
user 0m9,284s
sys 0m1,081s
优化后,即将 predicate_pushdown 与 projection_pushdown 均设置为 True。
real 0m1,732s
user 0m7,581s
sys 0m0,783s
可以看到,这一简单的优化使得我们节省了将近一半的查询时间!在现实应用中,业务数据通常保存了大量列, 我们预期这使得优化前后的过滤缺失数据、进行复杂的分组操作、关联操作等的性能差异会变得更大。
其它优化
除了谓词和投影下推之外,Polars还进行其他优化。
一个重要的主题是可选的缓存和并行化。很容易想象,有两种不同的DataFrame计算会导致扫描同一个文件Polars可能会缓存扫描的文件,以防止扫描同一文件两次。但是,如果您愿意,可以重写此行为并强制Polars读取同一文件。这可能会更快,因为扫描可以并行进行。
联结并行化
如果我们查看上一个查询,就会发现join操作有一个输入带有data/reddit.csv的计算路径作为根目录,一个路径带有data/runescape.csv作为根目录。Polars可以观察到两个DataFrame之间没有依赖关系,将并行读取这两个文件。如果在加入之前完成了其他操作(例如groupby、filters等),它们也会并行执行。
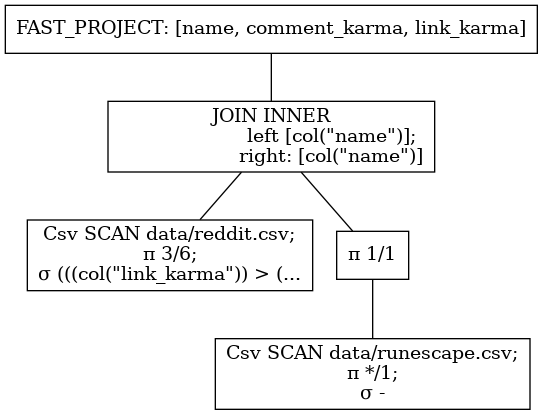
简化表达式
其他一些优化是表达式简化。这些优化的影响比谓词和投影下推的影响小,但它们很可能加起来。你可以追踪这个问题查看这些的最新状态。
参考指南
需要查看Polars的所有可用方法/功能吗?我们有Rust和Python的参考向导: