其它优化
除了谓词和投影下推之外,Polars还进行其他优化。
一个重要的主题是可选的缓存和并行化。很容易想象,有两种不同的DataFrame计算会导致扫描同一个文件Polars可能会缓存扫描的文件,以防止扫描同一文件两次。但是,如果您愿意,可以重写此行为并强制Polars读取同一文件。这可能会更快,因为扫描可以并行进行。
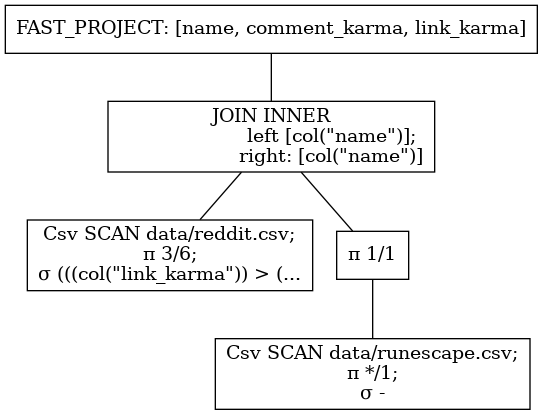
联结并行化
如果我们查看上一个查询,就会发现join操作有一个输入带有data/reddit.csv的计算路径作为根目录,一个路径带有data/runescape.csv作为根目录。Polars可以观察到两个DataFrame之间没有依赖关系,将并行读取这两个文件。如果在加入之前完成了其他操作(例如groupby、filters等),它们也会并行执行。
简化表达式
其他一些优化是表达式简化。这些优化的影响比谓词和投影下推的影响小,但它们很可能加起来。你可以追踪这个问题查看这些的最新状态。